📝 Paper Summary
Label-free Self-Improvement
Reinforcement Learning for Reasoning
Evol-RL prevents diversity collapse in label-free self-training by combining a stability reward (majority vote) with a novelty reward (reasoning path embedding similarity) to mimic evolutionary selection and variation.
Core Problem
Label-free self-improvement relying on internal consistency signals (like majority voting) drives models toward over-confident, narrow solutions, causing 'entropy collapse' where solution diversity and reasoning complexity degrade.
Why it matters:
- Real-world deployment requires learning from unlabeled data where ground truth verifiers are unavailable
- Current majority-driven methods actively punish correct but non-mainstream reasoning, reducing the model's ability to explore and causing performance on multi-attempt metrics (pass@n) to drop over time
- Models trained this way exhibit shorter, less complex reasoning chains, effectively memorizing simple paths rather than learning robust reasoning
Concrete Example:
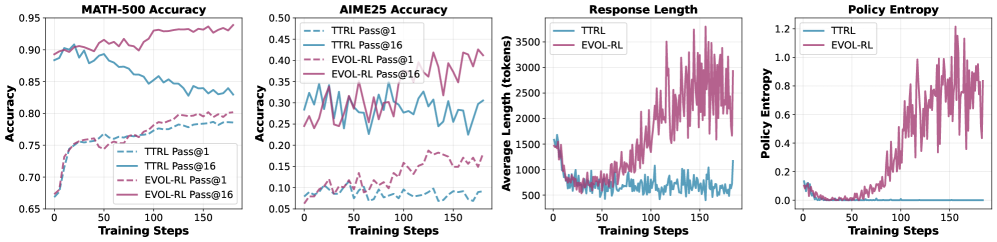
Under traditional Test-Time Reinforcement Learning (TTRL), a model trained on math problems might slightly improve its single-attempt accuracy (pass@1) but see its pass@16 drop significantly because it converges to a single, repetitive solution path, losing the ability to find alternative correct answers.
Key Novelty
Evol-RL (Evolution-Oriented Label-free RL)
- Applies evolutionary principles to RL: uses majority voting as 'Selection' to anchor correctness and a new intrinsic reward as 'Variation' to drive exploration
- Calculates a 'novelty score' for each response based on the semantic distance (embedding similarity) of its reasoning trace from other concurrent responses, rewarding unique reasoning paths even if they yield the same final answer
Architecture
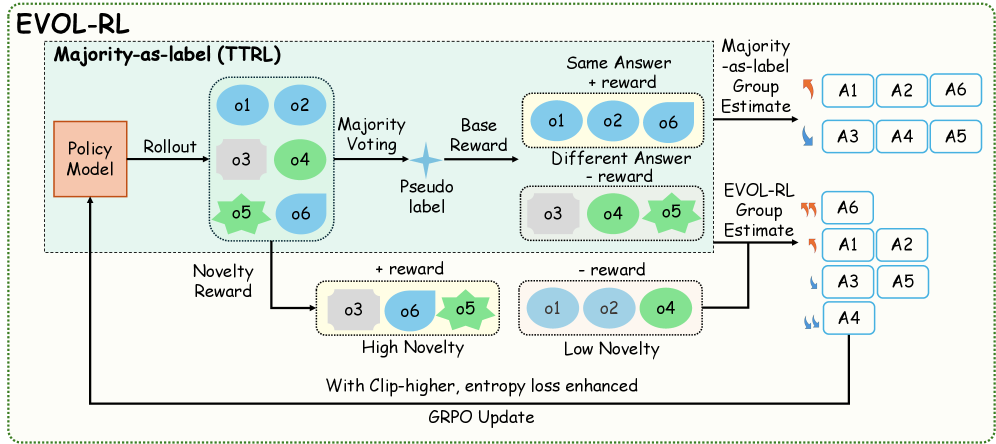
The Evol-RL framework: a policy generates a group of responses, which are scored by a majority vote (Selection) and a novelty estimator (Variation) based on embedding similarity, then updated via GRPO.
Evaluation Highlights
- Triples pass@1 accuracy on AIME25 (4.6% → 16.4%) and doubles pass@16 (18.5% → 37.9%) with Qwen3-4B-Base trained on label-free AIME24
- Outperforms majority-only baseline (TTRL) by +24.2% on AIME24 pass@16 with 4B model, reversing the typical diversity decline
- Achieves strong out-of-domain generalization: 4B model trained on simple MATH-500 matches the AIME24 performance of models trained directly on AIME24
Breakthrough Assessment
8/10
Addresses the critical 'entropy collapse' failure mode in self-training with a theoretically grounded, bio-inspired solution that delivers massive empirical gains on hard reasoning benchmarks.