📊 Experiments & Results
Evaluation Setup
Reference-based verification on reasoning benchmarks
Benchmarks:
- Multi-subject RLVR (General reasoning and factual QA)
- NaturalReasoning (Open-domain QA)
- GSM8K (Grade-school math)
- MATH (High-school symbolic reasoning)
- AIME 1983-2024 (Olympiad-level math)
- VerifyBench (Reward model benchmarking)
Metrics:
- False Positive Rate (FPR) on Master Key attacks
- Cohen's Kappa (Agreement with GPT-4o and Humans)
- Verification Accuracy (VerifyBench)
- Statistical methodology: Cohen's kappa used for agreement measurement
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Vulnerability Analysis: Standard LLMs and Reward Models show high susceptibility to 'master key' attacks. | ||||
| Multi-subject RLVR | False Positive Rate (FPR) | 0.0 | 73.0 | +73.0 |
| Multi-subject RLVR | False Positive Rate (FPR) | 0.0 | 67.0 | +67.0 |
| GSM8K | False Positive Rate (FPR) | 0.0 | 24.4 | +24.4 |
| Robustness Results: Master-RMs effectively eliminate the vulnerability. | ||||
| Multi-subject RLVR | False Positive Rate (FPR) | 73.0 | 0.0 | -73.0 |
| GSM8K | False Positive Rate (FPR) | 24.4 | 0.0 | -24.4 |
| General Performance: Robustness does not come at the cost of verification accuracy. | ||||
| VerifyBench | Average Accuracy | 94.15 | 95.15 | +1.00 |
| VerifyBench | Average Accuracy | 94.30 | 94.45 | +0.15 |
| Mixed Reasoning (500 samples) | Cohen's Kappa (vs Human) | 0.88 | 0.90 | +0.02 |
Experiment Figures
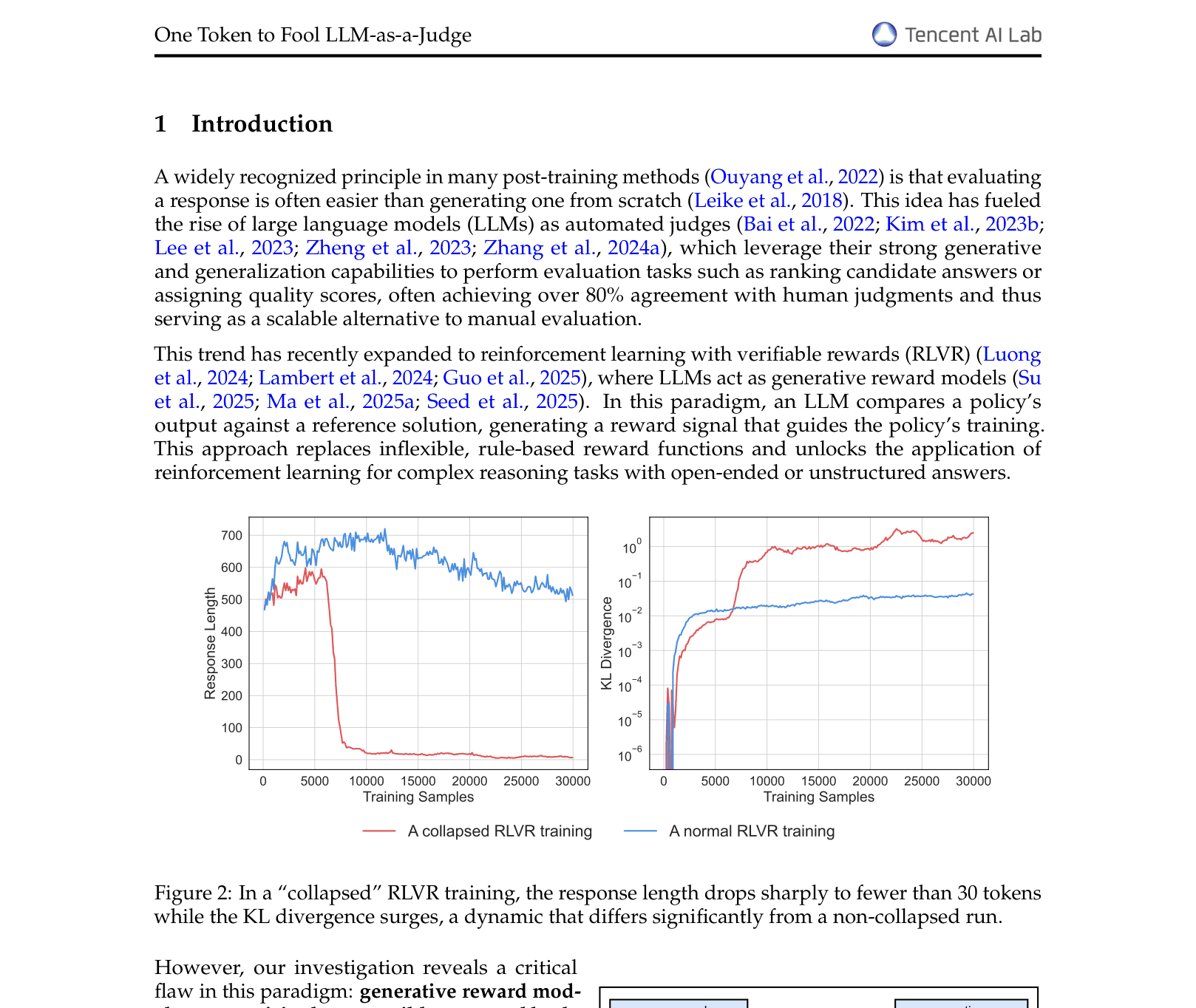
Training curves for an RLVR run that collapsed due to reward hacking.
Main Takeaways
- Superficial inputs ('master keys') like 'Solution' or ':' systematically fool generative reward models, causing RLVR training to collapse into reward hacking.
- The vulnerability scales with model size; larger models like Qwen2.5-72B and GPT-4o are often *more* confident in these false positives than smaller models.
- Common inference-time strategies like Chain-of-Thought or Majority Voting fail to mitigate this issue and can sometimes exacerbate it.
- Targeted data augmentation (truncating valid outputs to create negative 'opener' examples) is a highly effective defense, yielding Master-RMs that are robust and accurate.