📝 Paper Summary
Reinforcement Learning for LLMs
Mathematical Reasoning
RPG unifies KL-regularized policy gradient methods by deriving exact off-policy gradients for unnormalized KL divergences and stabilizing training via a clipped importance-weighted REINFORCE estimator.
Core Problem
Existing KL-regularized methods like GRPO often use ad-hoc estimators (e.g., k3) that lack correct importance weighting for off-policy sampling, leading to gradients that do not match the intended objective.
Why it matters:
- Current methods suffer from high variance or mathematical inconsistencies when training on data sampled from older policies (off-policy setting)
- Stability is critical for scaling RL to long-context reasoning tasks where exact on-policy sampling is computationally expensive
- Misaligned gradients in methods like GRPO can cause instability or suboptimal convergence in mathematical reasoning tasks
Concrete Example:
In GRPO, the KL penalty is estimated using the k3 estimator on samples from an old policy without an importance weight. This means the optimization direction is mathematically mismatched to the true KL-regularized objective, potentially leading to destructive updates.
Key Novelty
Regularized Policy Gradient (RPG) Framework
- Unifies normalized and unnormalized KL variants (Forward/Reverse) under a single derivation, proving the popular k3 estimator is exactly the unnormalized Reverse KL
- Identifies and corrects the missing importance weight in GRPO's KL term, deriving a surrogate loss that yields the exact gradient of the intended objective
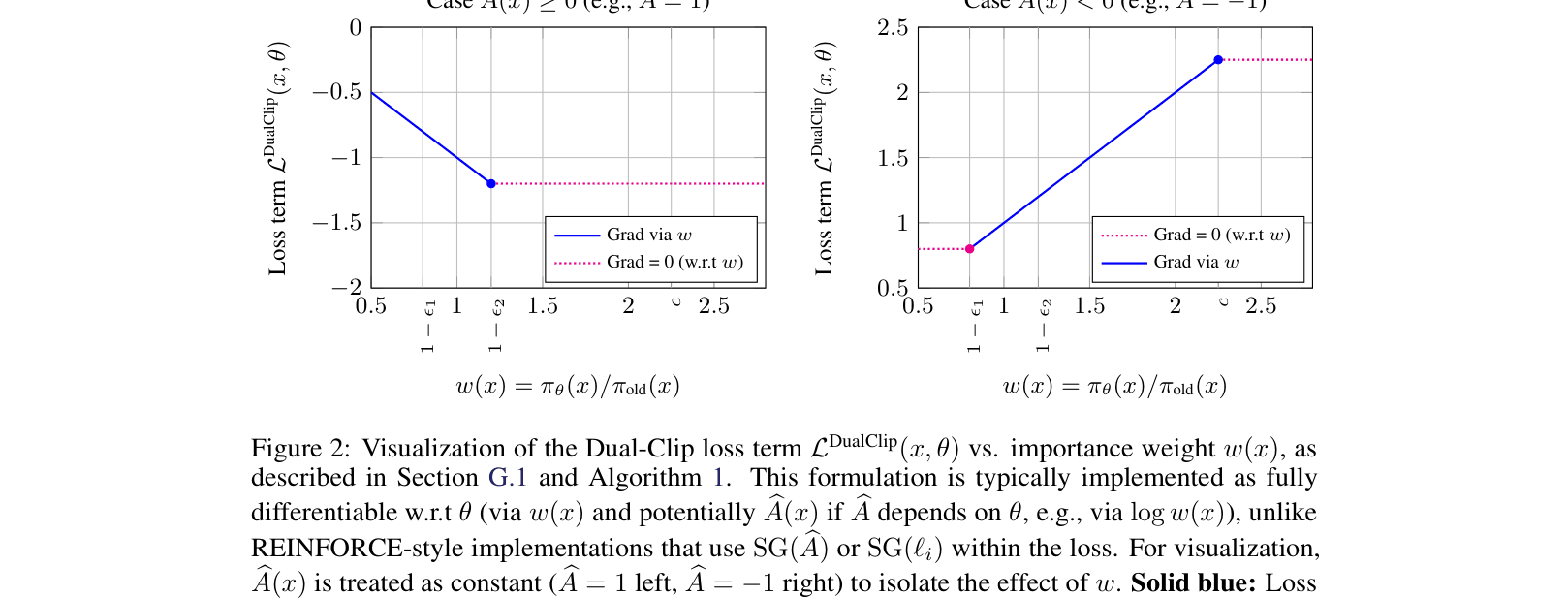
- Introduces RPG-Style Clip, a dual-clipped REINFORCE estimator that stabilizes off-policy updates by bounding importance ratios based on the sign of the regularized advantage
Architecture
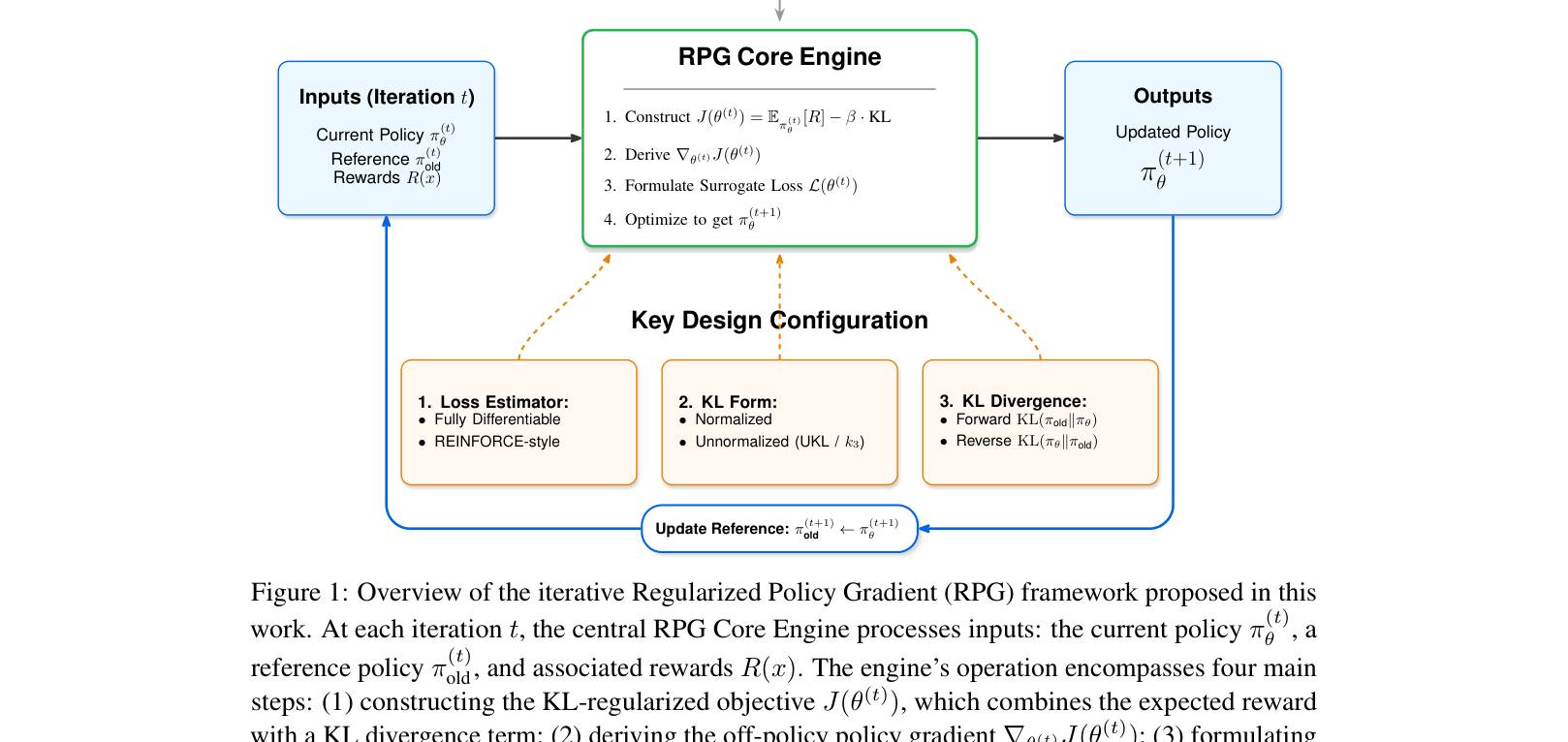
Overview of the iterative Regularized Policy Gradient (RPG) framework and its core engine.
Evaluation Highlights
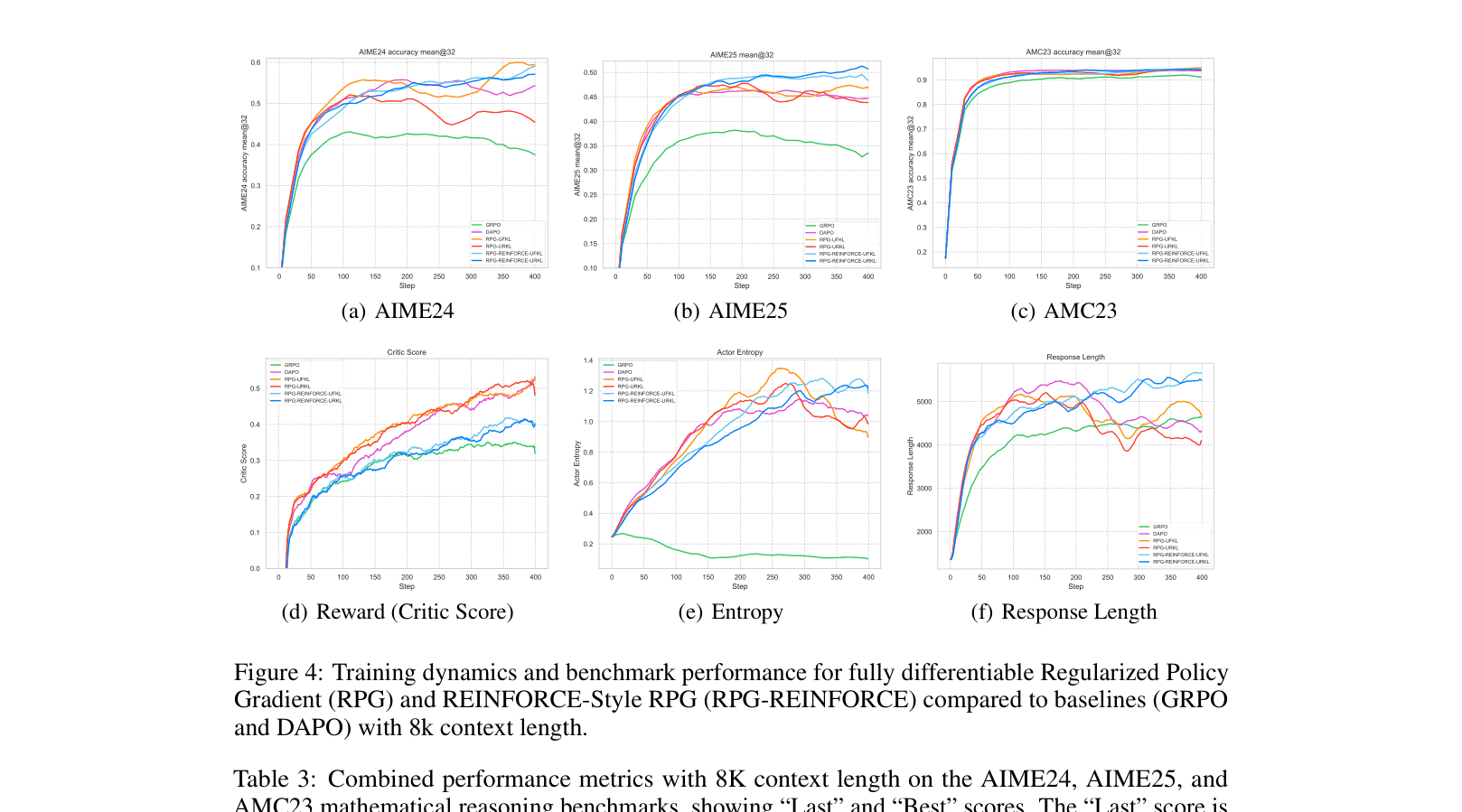
- Achieves 52.08% accuracy on AIME25 with Qwen3-4B (8K context), surpassing the official Qwen3-4B-Instruct model (47%)
- RPG-REINFORCE outperforms the strong DAPO baseline by +4.68 percentage points on AIME25 and +2.18 points on AIME24
- Demonstrates superior stability in reward and entropy curves compared to GRPO, which suffers from higher volatility due to incorrect weighting
Breakthrough Assessment
9/10
Provides a rigorous theoretical unification of scattered KL-regularized methods and corrects a fundamental weighting error in the widely used GRPO, while delivering state-of-the-art reasoning performance.