📝 Paper Summary
Egocentric Video Understanding
Spatial-Temporal Reasoning
Multimodal Large Language Models (MLLMs)
The paper introduces a benchmark for egocentric video reasoning and a training paradigm that uses reverse thinking (retracing paths) to teach models spatial-temporal logic via reinforcement learning.
Core Problem
Current Multimodal Large Language Models (MLLMs) struggle with complex spatial-temporal reasoning in 4D worlds, specifically failing to understand ego-motion trajectories, directional changes, and environmental context over time.
Why it matters:
- Egocentric video understanding is critical for embodied AI (robots, autonomous vehicles) which must navigate and interpret dynamic human-centric environments.
- Existing benchmarks focus on static spatial properties (object size, distance) or simple video QA, lacking rigorous tests for navigation, route description, and reasoning about time and space together.
- Prior methods like VSI-Bench identify spatial reasoning as a bottleneck but do not address the temporal evolution of spatial relationships in video.
Concrete Example:
When asked to describe a route taken in a video, current models often hallucinate landmarks or mix up the sequence of turns. For example, they might fail to deduce the starting point by mentally reversing the observed path, a task humans perform naturally.
Key Novelty
Reverse Thinking as a Reasoning Mechanism
- Introduces 'Reverse Thinking' where the model learns to reason about a route by mentally retracing it backwards, mimicking human cognitive processes for spatial recall.
- Uses this reverse perspective to construct Chain-of-Thought (CoT) data: the forward path becomes the reasoning trace for the reverse question, and vice versa.
- Trains the model using Group Relative Policy Optimization (GRPO), a reinforcement learning technique, to refine this bidirectional reasoning capability without a separate critic model.
Architecture
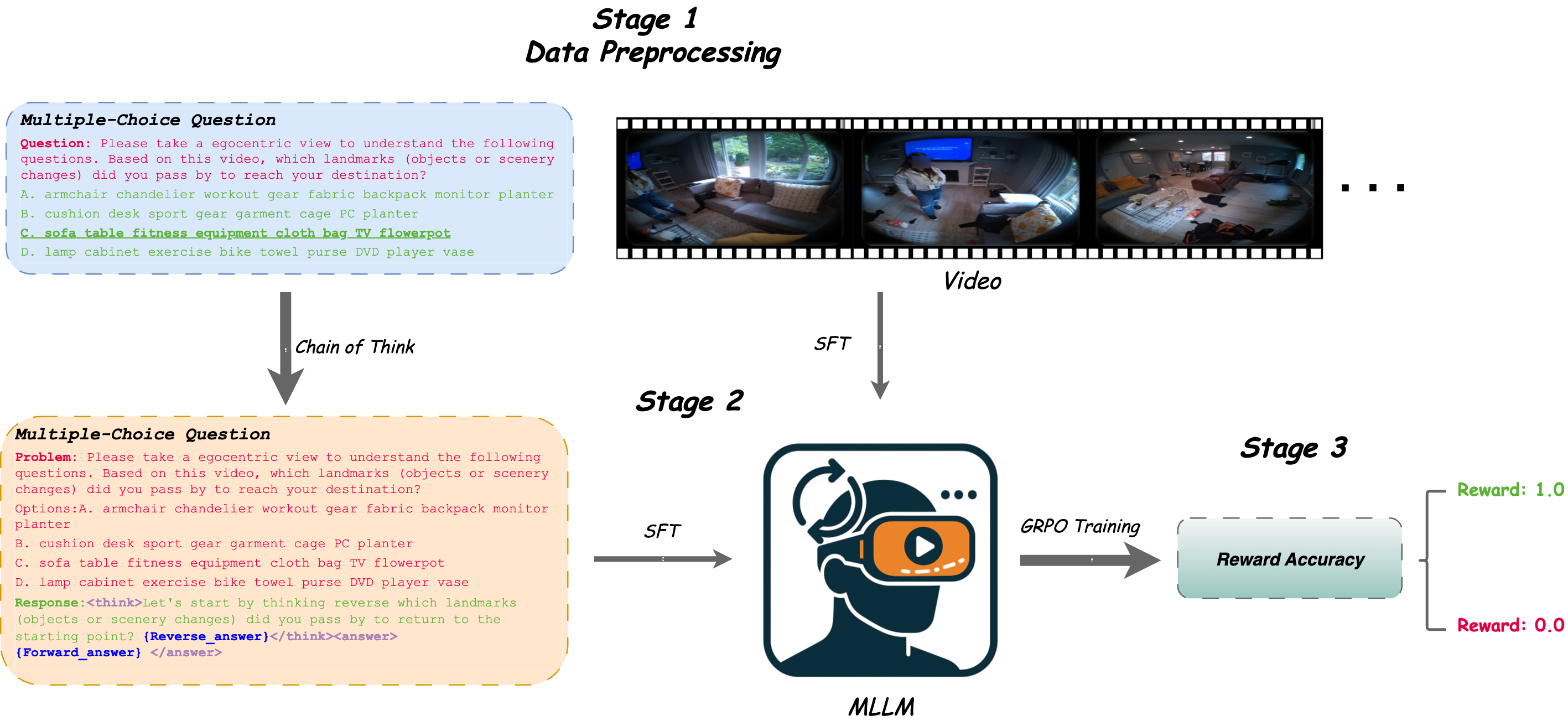
The training pipeline for ST-R1, illustrating the two-stage process: CoT SFT followed by GRPO Reinforcement Learning.
Evaluation Highlights
- The proposed ST-R1 model significantly enhances performance over traditional Supervised Fine-Tuning (SFT) methods by leveraging the multi-stage post-training strategy.
- Open-source models with long context windows perform comparably to closed-source models on the new Ego-ST Bench, challenging the assumption that proprietary models are strictly superior in this domain.
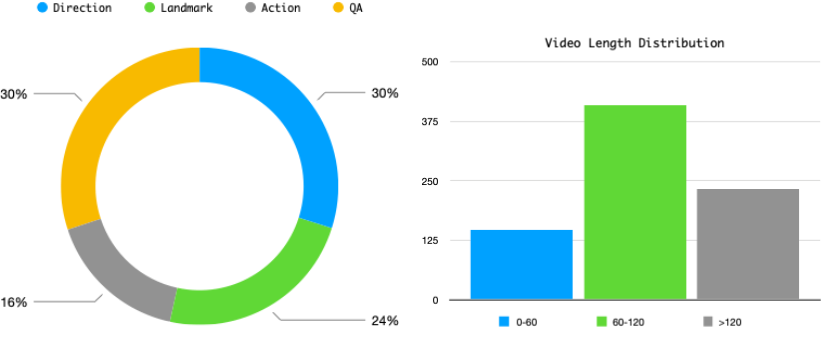
- The Ego-ST Bench establishes a new standard with over 5,000 annotated instances across 789 video clips, specifically testing forward and reverse reasoning capabilities.
Breakthrough Assessment
8/10
Significant contribution by introducing the first bidirectional (forward/reverse) spatial-temporal benchmark and a novel RL-based training paradigm that explicitly models reverse thinking for video reasoning.