📊 Experiments & Results
Evaluation Setup
Multiple-choice question answering on the AVQA-R1-6K dataset
Benchmarks:
- AVQA-R1-6K (Audio-Visual Question Answering) [New]
Metrics:
- Accuracy (%)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| AVQA-R1-6K Validation Set | Accuracy | 80.53 | 85.77 | +5.24 |
Experiment Figures

Qualitative examples of 'aha moments' during reasoning
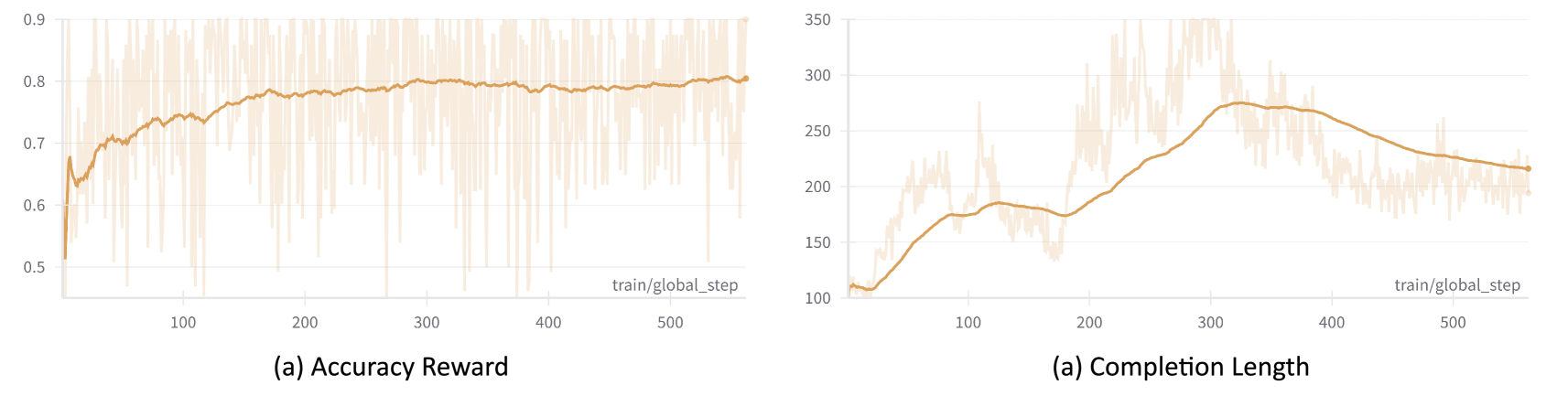
Training dynamics: Accuracy reward and Completion length over steps
Main Takeaways
- Reinforcement learning (GRPO) significantly enhances multimodal reasoning with minimal fine-tuning steps.
- The model exhibits emergent self-correction ('aha moments') where it revises initial assumptions based on cross-modal evidence.
- Training dynamics show a two-phase process: initial expansion of reasoning length followed by contraction into concise, effective traces.