📝 Paper Summary
Visual Reasoning
Tool-Augmented Multimodal LLMs
Reinforcement Learning for Reasoning
ReVPT improves the visual perception of multimodal language models by training them to reason with and use visual tools (like depth estimation and object detection) using Group Relative Policy Optimization (GRPO).
Core Problem
Supervised fine-tuning (SFT) for visual tool use is limited because it relies on expensive, pre-defined trajectories that don't incentivize the model to explore alternative tools or adapt to new visual environments.
Why it matters:
- Visual reasoning requires complex perception (depth, edges) that standard VLM embeddings often miss
- SFT models struggle to generalize because they memorize fixed tool sequences rather than learning the logic of *when* to use a tool
- Existing tool-use approaches rely heavily on expensive GPT-4 generated traces that require aggressive filtering
Concrete Example:
When asked to identify an object's distance, a standard VLM might guess based on 2D features. An SFT-trained tool model might call a depth tool but fail to interpret the color-coded map correctly if the map differs from its training data. ReVPT allows the model to explore different interpretations of the tool output during training to find the correct answer.
Key Novelty
Reinforced Visual Perception with Tools (ReVPT)
- Replaces static SFT trajectories with a reinforcement learning phase (GRPO) where the model explores different tool combinations to solve visual queries
- Uses a 'Cold Start' phase with synthetic data to teach basic tool syntax, followed by RL optimization driven by simple binary rewards (correctness and format)
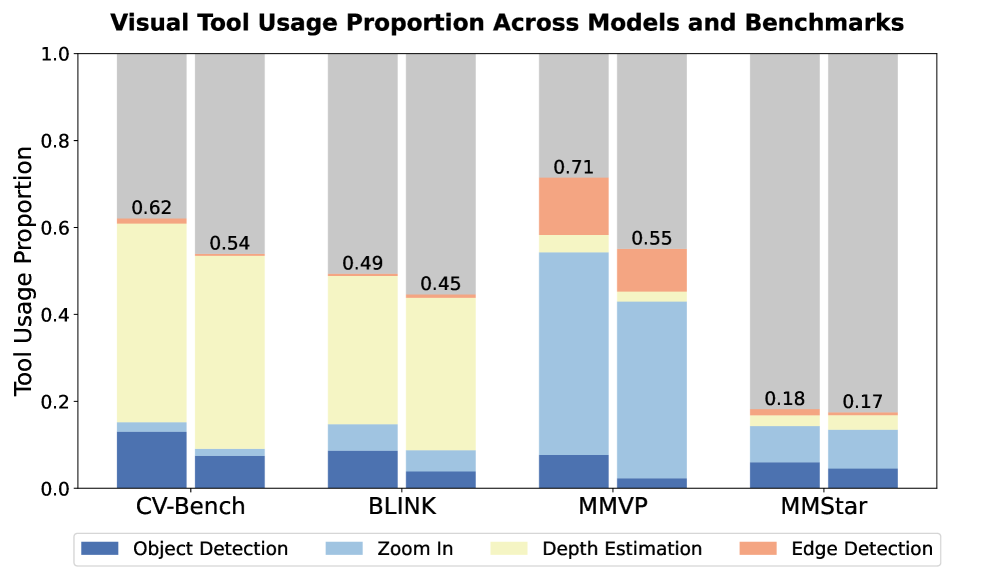
- Integrated suite of four specific perceptual tools (detection, zoom, edge, depth) treated as reasoning steps within the generation process
Architecture
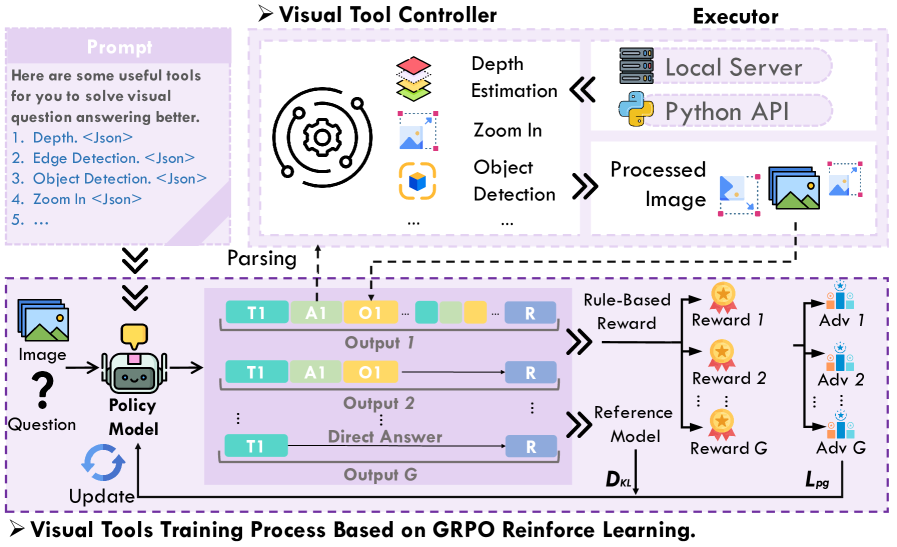
The overall architecture of the ReVPT framework.
Evaluation Highlights
- ReVPT-7B outperforms the base Qwen2.5-VL-7B-Instruct by +9.82% on the perception-heavy CV-Bench benchmark
- Outperforms commercial giants GPT-4.1 and Gemini-2.0-Flash on the challenging BLINK-Depth and BLINK-Relation subsets
- ReVPT-3B achieves a +8.65% improvement on CV-Bench compared to its instruct baseline, showing scalability across model sizes
Breakthrough Assessment
8/10
Strong application of recent RL reasoning advances (GRPO) to the visual tool-use domain. Demonstrates significant gains over SFT baselines, addressing a key bottleneck in multimodal agent reliability.