📝 Paper Summary
Decentralized Machine Learning
Distributed Reinforcement Learning
Reasoning Models
INTELLECT-2 demonstrates the first successful training of a 32B parameter reasoning model using fully asynchronous reinforcement learning across a globally distributed, permissionless network of consumer-grade GPUs.
Core Problem
Training large reasoning models with reinforcement learning typically requires massive, centralized clusters with fast interconnects, creating a high barrier to entry and resource bottleneck.
Why it matters:
- Centralized training concentrates AI development power in few organizations with massive capital
- Reinforcement learning is inherently asynchronous and doesn't require the tight synchronization of pre-training, representing an untapped opportunity for distributed compute
- Vast amounts of consumer-grade GPU compute are currently underutilized and disconnected from high-value AI training workflows
Concrete Example:
In a standard centralized setup, if one node hangs, the entire training run often stalls. In INTELLECT-2, if a contributor node (e.g., a home gaming PC) disconnects or acts maliciously, the central trainer simply ignores it and continues updating the policy using data from other nodes.
Key Novelty
Fault-tolerant Asynchronous Distributed RL at Scale
- Decouples rollout generation (inference) from model updates (training) so that thousands of heterogeneous devices can contribute data at their own pace without slowing down the central learner
- Uses 'toploc', a locality-sensitive hashing scheme, to cryptographically verify that untrusted contributors actually ran the correct model and didn't fake the data
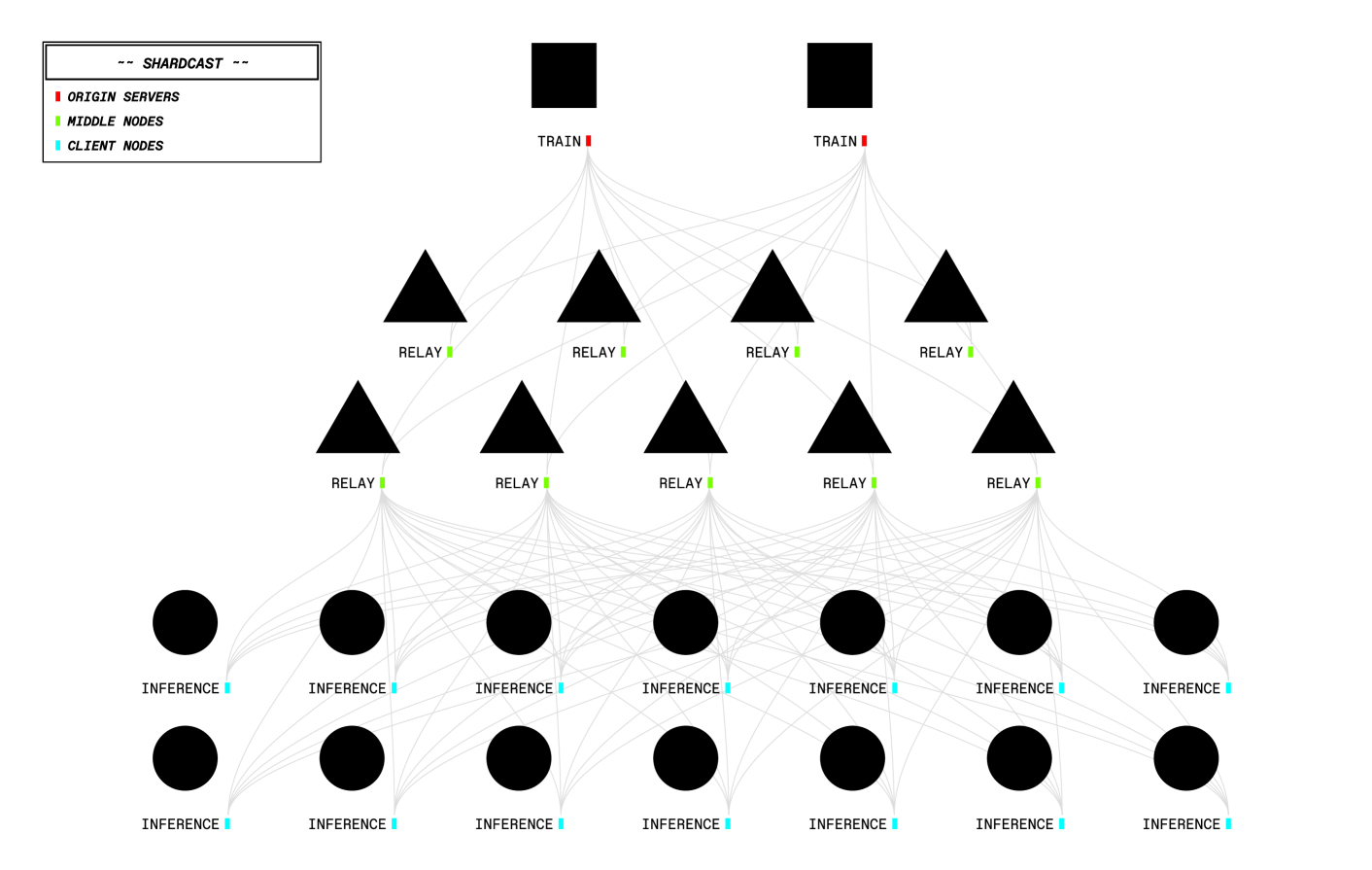
- Distributes massive model weights via 'shardcast', a peer-assisted delivery network that acts like a CDN for model checkpoints
Architecture

The Intellect-2 decentralized training infrastructure showing the three main roles and their interactions.
Evaluation Highlights
- Successfully trained a 32B parameter model (Intellect-2) on distributed consumer hardware, improving upon QwQ-32B (state-of-the-art in 32B range)
- toploc verification overhead is only ~1% reduction in tokens-per-second throughput while catching tampering
- Demonstrated stable GRPO training with fully asynchronous rollouts, proving high-speed interconnects are not strictly necessary for RL fine-tuning
Breakthrough Assessment
9/10
A major engineering milestone: proving that large-scale RL training for LLMs works on permissionless, decentralized networks. It breaks the assumption that top-tier model training requires centralized clusters.