📝 Paper Summary
Multimodal Reasoning
Reinforcement Learning from Human Feedback (RLHF)
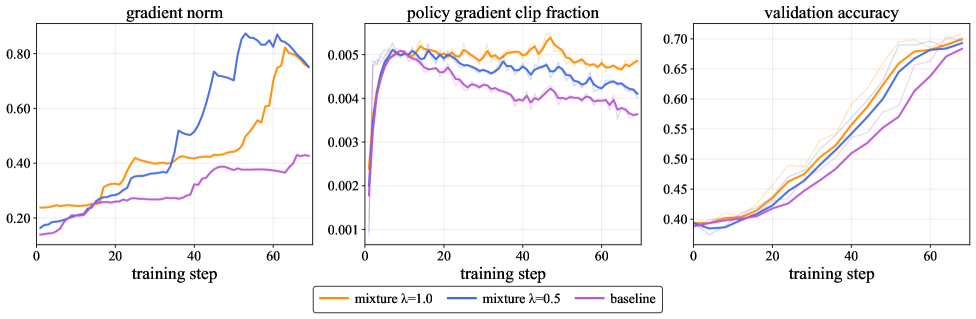
MMR1 stabilizes multimodal reinforcement learning by dynamically sampling prompts that maximize reward variance—balancing correct and incorrect outcomes and diverse reasoning paths—to prevent gradient vanishing.
Core Problem
Group Relative Policy Optimization (GRPO) suffers from gradient vanishing when sampled rewards have low variance (e.g., all correct or all incorrect), weakening optimization signals.
Why it matters:
- Standard RL fine-tuning often collapses because relative advantages approach zero without variance, wasting computation and stalling learning.
- Existing multimodal datasets lack the scale and quality of long Chain-of-Thought (CoT) data needed for effective reasoning, constraining reproducibility.
- Current solutions like filtering by pass rate are heuristic and lack theoretical guarantees regarding gradient magnitude.
Concrete Example:
If a model answers a hard math problem incorrectly 32 out of 32 times, the reward variance is zero. GRPO computes advantages relative to the group mean (also zero), resulting in zero gradients and no learning update, even though the model failed.
Key Novelty
Variance-Aware Sampling (VAS)
- Selects training data based on a Variance Promotion Score (VPS) that prioritizes prompts likely to yield mixed outcomes (some right, some wrong) and diverse reasoning paths.
- Combines Outcome Variance Score (OVS), which targets a 50% pass rate, with Trajectory Diversity Score (TDS), which ensures gradient signal even when correctness feedback is sparse.
- Mixes this targeted sampling with uniform random sampling to ensure broad distribution coverage while boosting optimization stability.
Architecture
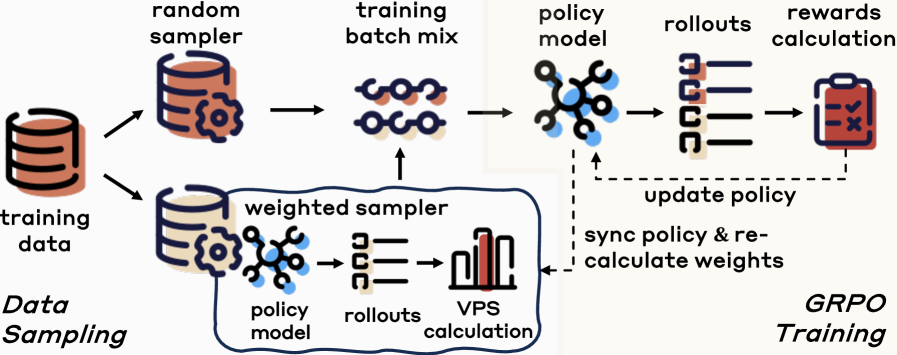
Overview of the MMR1 framework illustrating the Variance-Aware Sampling (VAS) mechanism within the RL loop.
Evaluation Highlights
- MMR1-7B achieves state-of-the-art average score of 58.4 across 5 multimodal reasoning benchmarks, surpassing comparable reasoning models like R1-VL-7B (47.7).
- On MathVerse, MMR1-7B scores 55.4, outperforming Qwen2.5-VL-7B (50.4) and InternVL2.5-8B (40.0).
- MMR1-3B (small scale) achieves 52.7 average, matching or exceeding several 7B baselines like OpenVLThinker-7B (52.5).
Breakthrough Assessment
8/10
Provides a theoretically grounded solution to RL gradient vanishing via data sampling and releases significant high-quality open resources (1.6M CoT data), addressing both algorithmic and data bottlenecks.