📝 Paper Summary
GUI Automation
Agentic AI
Safety and Verification
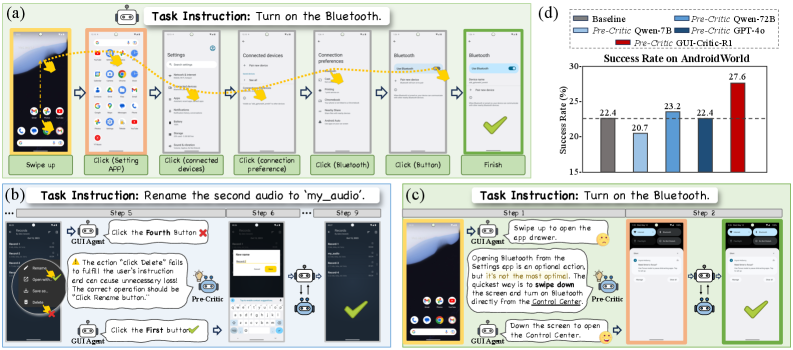
GUI-Critic-R1 is a specialized 7B model that diagnoses potential errors in GUI automation actions before execution, trained using a Suggestion-aware Group Relative Policy Optimization strategy to provide corrective feedback.
Core Problem
Current MLLM-based GUI agents lack the ability to self-reflect effectively in real-time, leading to cumulative errors that can be irreversible (e.g., deletion) or inefficient.
Why it matters:
- GUI automation operates in online environments where single-step errors can disrupt the entire process or cause irreversible damage like accidental payments or file deletions
- Existing agents often select sub-optimal paths with redundant steps, reducing efficiency
- Closed-source models are too costly/slow for real-time checks, while open-source models struggle with GUI-specific reasoning and forecasting
Concrete Example:
Given an instruction to 'Rename the current audio', an agent might predict clicking a 'delete' button instead of 'rename'. Without pre-execution critique, the file is permanently lost. A pre-critic would catch this by analyzing the icon and predicting the deletion outcome.
Key Novelty
Pre-operative Critic Mechanism with Suggestion-aware GRPO (S-GRPO)
- Introduces a 'look before you leap' mechanism where a separate critic model evaluates an agent's proposed action *before* execution to prevent dangerous or inefficient steps
- Proposes S-GRPO, a reinforcement learning strategy that uses a novel 'suggestion reward' to force the critic to generate valid corrective actions, not just binary judgments
- Develops a 'reasoning bootstrapping' pipeline to generate synthetic Chain-of-Thought training data for GUI critiques without needing expensive human annotation
Architecture
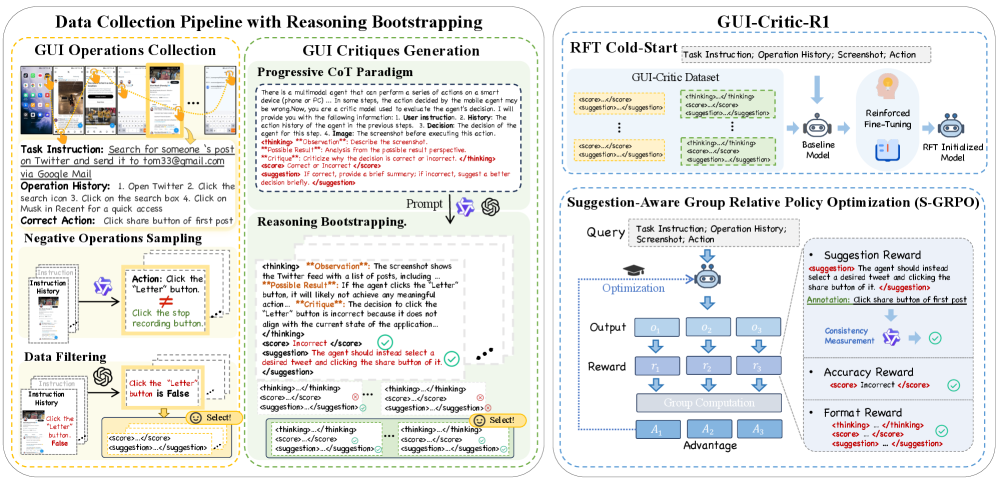
The overall framework of the GUI-Critic-R1 training pipeline, including Data Construction and Suggestion-aware GRPO.
Evaluation Highlights
- +5.2% success rate improvement (22.4% to 27.6%) on the AndroidWorld benchmark when integrating GUI-Critic-R1 into a baseline agent
- Outperforms GPT-4o in critic accuracy on the GUI-Critic-Test dataset (Exact Match score of 91.0 vs 86.8)
- Achieves 86.1% Suggestion Validity Score, significantly higher than Qwen2-VL-7B (31.7%) and close to GPT-4o (88.6%)
Breakthrough Assessment
8/10
First comprehensive pre-operative critic for GUI agents. Strong methodology (S-GRPO) and solid results surpassing GPT-4o in specific critic tasks, though limited to a 7B model scale.