📝 Paper Summary
Vision-Language-Action (VLA) Models
Model-based Reinforcement Learning
World Models
WMPO trains robot policies entirely within a learned pixel-space video world model using on-policy RL, aligning imagined dynamics with VLA visual priors to avoid costly real-world interactions.
Core Problem
VLA policies trained via imitation learning are brittle to out-of-distribution states, while real-world reinforcement learning is prohibitively sample-inefficient and unsafe.
Why it matters:
- Collecting millions of real-world interaction trials for RL is impractical and dangerous for physical hardware
- Existing latent-state world models discard the rich pixel-level visual features that VLA models rely on, creating a representation mismatch
- Manual simulator design for diverse real-world scenarios has high engineering overhead
Concrete Example:
A robot trained only on successful demonstrations might fail to grasp a cup. In the real world, it would need thousands of failed attempts to learn a correction, risking damage. In a standard latent world model, the visual details of the cup handle might be lost, preventing the VLA from 'seeing' the correct grasp pose in imagination.
Key Novelty
World Model-based Policy Optimization (WMPO)
- Replaces real-world RL rollouts with 'imagined' trajectories generated by a pixel-space video world model, allowing the VLA to perform on-policy learning safely
- Aligns the world model to the policy's specific behavior by fine-tuning on a small set of real policy rollouts (including failures), ensuring the simulator accurately reflects the agent's current capabilities
- Utilizes a pixel-space diffusion backbone (rather than latent dynamics) to ensure the generated observations remain compatible with the VLA's pretrained visual encoders
Architecture
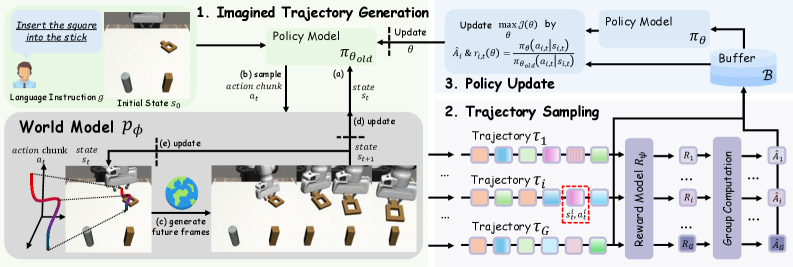
Overview of the WMPO training procedure, illustrating the cycle of imagination, evaluation, and optimization
Breakthrough Assessment
8/10
Proposes a scalable path for VLA RL by effectively substituting the physical world with a high-fidelity video generative model, addressing the critical sample efficiency bottleneck.