📝 Paper Summary
Multimodal Large Language Models (MLLMs)
Reinforcement Learning (RL) for Reasoning
Video Question Answering
TW-GRPO improves video reasoning by weighting tokens based on information entropy to focus thinking and using multi-choice soft rewards to distinguish partial correctness.
Core Problem
Current RL-based multimodal reasoning produces verbose, unfocused chains of thought and relies on sparse binary rewards that fail to credit partially correct answers.
Why it matters:
- Verbose reasoning often obscures critical spatio-temporal cues, leading to inefficiency and hallucination (overthinking)
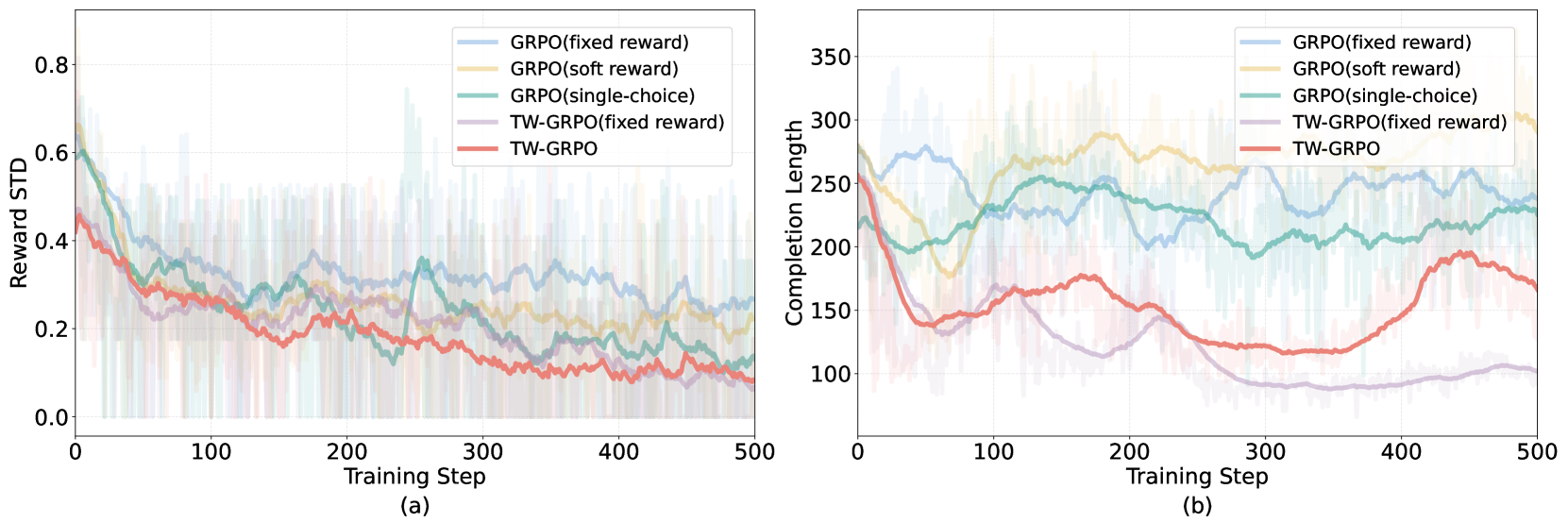
- Binary rewards (0 or 1) cause high variance during training because they cannot distinguish between a 'close' answer and a completely wrong one, hindering stable policy updates
Concrete Example:
In a video QA task, if the ground truth is {B, D} and the model predicts {B}, standard methods give 0 reward (incorrect). TW-GRPO gives a partial reward (0.5), acknowledging the correct component.
Key Novelty
Token-Weighted Group Relative Policy Optimization (TW-GRPO)
- Uses intra-group information entropy to identify and upweight 'informative' tokens (those where candidate responses diverge) while downweighting generic filler phrases like 'Let's think'
- Reformulates single-choice QA into multi-choice tasks with 'soft rewards' based on set overlap (IoU-like), allowing the model to learn from partially correct predictions
Architecture
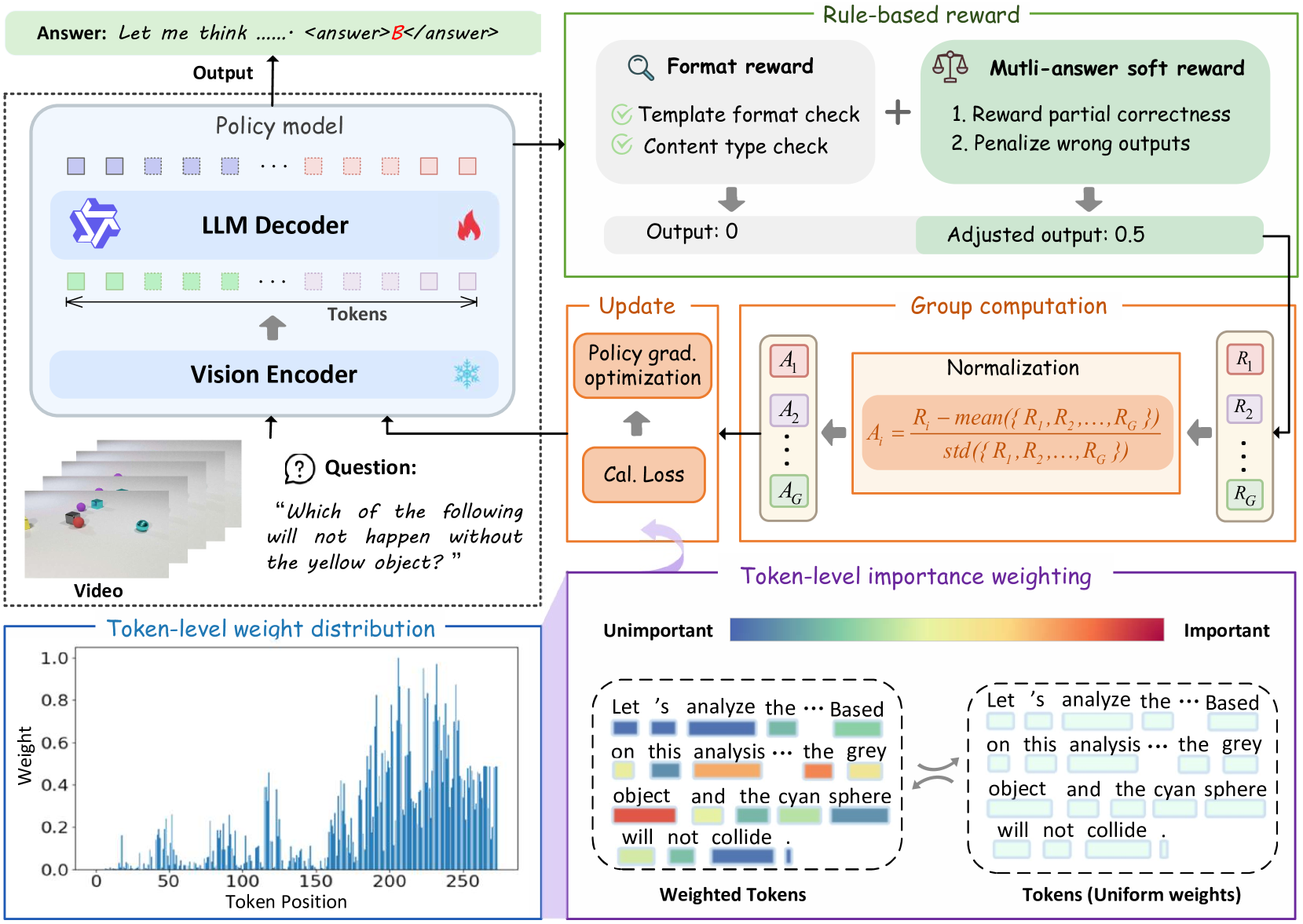
Overview of the TW-GRPO framework illustrating the flow from policy sampling to loss computation.
Evaluation Highlights
- Achieves 50.4% accuracy on CLEVRER, outperforming the Video-R1 baseline by +18.8%
- Surpasses Video-R1 by +1.6% on MMVU and +1.8% on NExT-GQA benchmarks
- Significantly reduces reward variance during training compared to standard single-choice binary reward baselines
Breakthrough Assessment
7/10
Significant improvement on complex reasoning benchmarks (CLEVRER). The shift to soft rewards for QA and entropy-based token weighting is a clever, methodologically sound refinement of GRPO.