📝 Paper Summary
Reinforcement Learning for Reasoning
Interpretability of RL Dynamics
RL improves reasoning not by monolithic optimization, but by a two-phase process—first mastering procedural execution, then exploring high-level strategic planning—which HICRA exploits by concentrating learning signals on planning tokens.
Core Problem
The mechanisms driving RL success in reasoning (e.g., 'aha moments', 'length-scaling') are poorly understood, and current algorithms apply optimization pressure inefficiently across all tokens regardless of their importance.
Why it matters:
- Prevailing methods like GRPO dilute the learning signal by treating high-impact strategic tokens and low-level formatting tokens equally
- Lack of understanding regarding *why* RL works hinders the design of more principled algorithms that could accelerate reasoning capabilities
Concrete Example:
In a math solution, a strategic phrase like 'Let's try a different approach' determines the solution path, while 'so we add 5' is a routine execution. Standard RL rewards both equally if the answer is correct, failing to prioritize the critical strategic decision.
Key Novelty
Hierarchy-Aware Credit Assignment (HICRA) & Strategic Gram Analysis
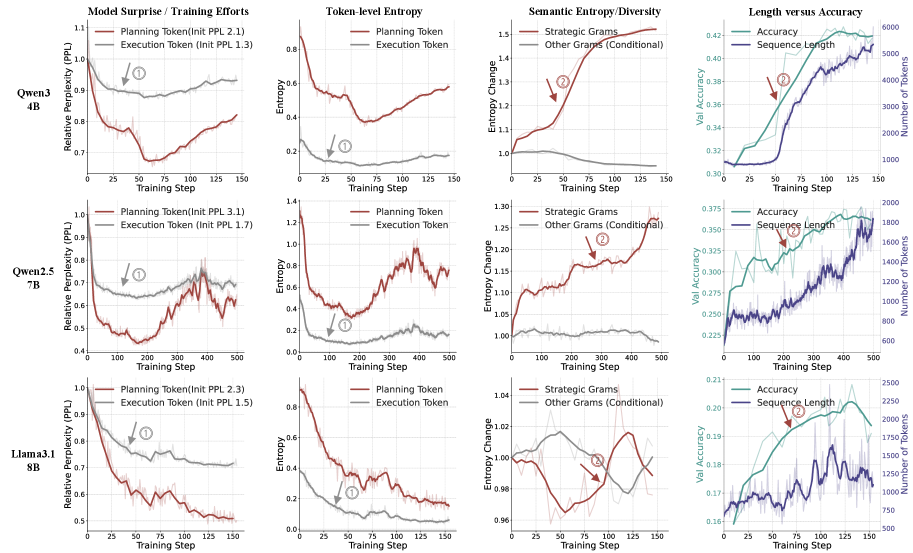
- Decomposes reasoning into 'planning tokens' (strategic moves) and 'execution tokens' (procedural steps) using a functional proxy called Strategic Grams
- Identifies a two-phase learning dynamic where models first master low-level procedures, then shift the learning bottleneck to exploring high-level strategies
- Proposes HICRA to selectively amplify optimization pressure on planning tokens, aligning the learning algorithm with the emergent hierarchical structure of reasoning
Architecture

The construction and classification of 'Strategic Grams' (SGs). It illustrates how n-grams are extracted, clustered semantically, and filtered by document frequency to create a functional proxy for planning tokens.
Evaluation Highlights
- Identifies a 'Strategic Exploration Phase' where performance gains correlate with increased Semantic Entropy of planning tokens, explaining 'aha moments' and length-scaling
- Demonstrates that removing 30% of identified Strategic Grams does not alter the observed learning dynamics, validating the robustness of the functional proxy
- Qualitatively outperforms agnostic credit assignment baselines (GRPO) by focusing optimization on the strategic bottleneck (specific numeric deltas not in provided text)
Breakthrough Assessment
8/10
Provides a compelling, unified theoretical framework for opaque RL phenomena (aha moments, entropy shifts) and translates this insight directly into a modified algorithm (HICRA).