📝 Paper Summary
Multimodal Large Language Models (MLLMs)
Visual Segmentation
Seg-R1 equips multimodal models with pixel-level segmentation capabilities by using reinforcement learning to generate optimal bounding box and point prompts for a frozen SAM2 model, eliminating the need for specialized decoder architectures.
Core Problem
Current Large Multimodal Models (LMMs) require specialized tokens and decoder architectures to perform segmentation, which disrupts the causal modeling of LLMs and relies on expensive, large-scale pixel-level supervised fine-tuning.
Why it matters:
- Architectural modifications (special tokens) disrupt the continuity of standard causal language models
- Supervised fine-tuning (SFT) on pixel tasks often leads to catastrophic forgetting of general multimodal capabilities
- Existing methods struggle to generalize to open-world segmentation tasks (like reasoning segmentation) without explicit supervision on those specific datasets
Concrete Example:
When fine-tuned via SFT for segmentation, a model's performance on general benchmarks like MMBench drops significantly. In contrast, Seg-R1 uses RL to learn segmentation prompting without losing general visual understanding.
Key Novelty
Reinforcement Learning for Mask Prompting
- Instead of outputting masks directly, the LMM learns to function as an 'annotator' that generates reasoning chains and sparse prompts (points, boxes) to guide a frozen SAM2 model
- Uses Group Relative Policy Optimization (GRPO) to optimize the LMM's prompting strategy based on the final mask quality (IoU + S-Measure), bypassing the need for dense pixel-level gradients for the LMM itself
Architecture
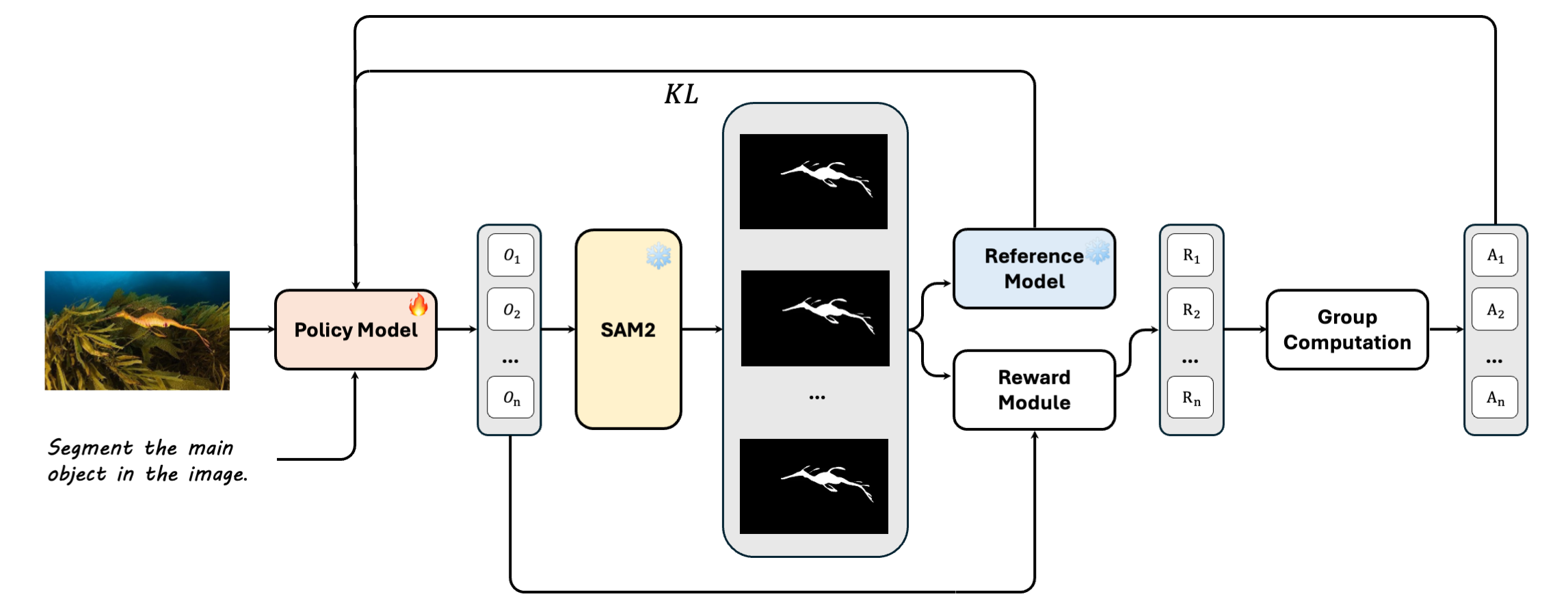
The GRPO training framework for Seg-R1.
Evaluation Highlights
- 0.873 S-measure on COD10K-Test (Camouflaged Object Detection), achieved with pure RL training
- 0.878 S-measure on DUT-OMRON (Salient Object Detection), achieving state-of-the-art performance after fine-tuning
- 71.4 cIoU on RefCOCOg test (Zero-shot), demonstrating generalization to referring segmentation without training on referring data
Breakthrough Assessment
8/10
Demonstrates that pure RL can replace complex architectural modifications for segmentation, achieving strong zero-shot generalization and SoTA results while preserving general model capabilities.
