📝 Paper Summary
Large Audio-Language Models (LALMs)
Reinforcement Learning for Reasoning
SARI enhances audio-language models by combining structured chain-of-thought supervised fine-tuning with curriculum-guided reinforcement learning to improve multi-step reasoning.
Core Problem
Current Large Audio-Language Models (LALMs) excel at perception but lack explicit multi-step reasoning capabilities, often failing at complex audio analysis tasks.
Why it matters:
- Existing models primarily handle straightforward QA but struggle with complex reasoning required for real-world audio understanding
- Applying reinforcement learning to audio reasoning is underexplored compared to text-only domains
- Simple RL application without structured guidance often fails to induce correct reasoning or improve performance on difficult audio tasks
Concrete Example:
When asked to identify a 'whoop' sound source, a standard model might guess 'Human' without explanation. SARI explicitly plans, captions ('loud, sharp vocalization'), reasons ('compare with bird/machine sounds'), and summarizes to confirm 'Human', avoiding errors through self-correction.
Key Novelty
Structured Audio Reasoning via Curriculum-Guided RL (SARI)
- Extends DeepSeek-R1's Group-Relative Policy Optimization (GRPO) to the audio modality, rewarding models for correct reasoning paths
- Implements a 'structured' Chain-of-Thought (CoT) format requiring explicit Planning, Captioning, Reasoning, and Summarizing steps
- Uses a curriculum learning schedule during RL that orders training samples from easy to hard based on baseline pass rates, preventing the policy from collapsing on difficult examples
Architecture
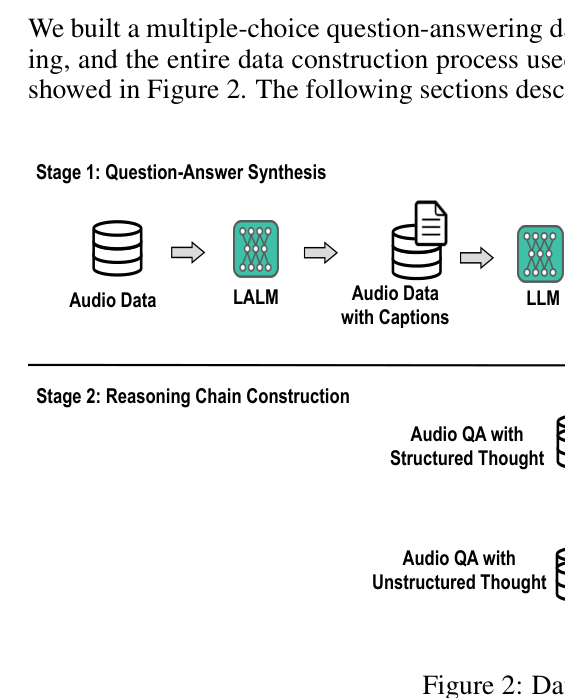
The Data Construction and Training pipeline. It illustrates how audio data is processed via LLMs to create structured and unstructured thought data, followed by filtering for RL, and then split into SFT and RL phases.
Evaluation Highlights
- Achieves state-of-the-art 67.08% accuracy on the MMAU test-mini benchmark using Qwen2.5-Omni as the base, surpassing standard supervised fine-tuning
- +16.35% improvement in average accuracy over the Qwen2-Audio-7B-Instruct base model on MMAU test-mini
- Curriculum learning adds +1.97% accuracy over standard randomized RL training on the MMAU benchmark
Breakthrough Assessment
8/10
Significantly advances audio reasoning by successfully transferring text-based RL reasoning techniques (GRPO) to audio, demonstrating that structured thought and curriculum are essential for this modality.