📝 Paper Summary
Multimodal Large Language Models (MLLMs)
Reinforcement Learning (RL)
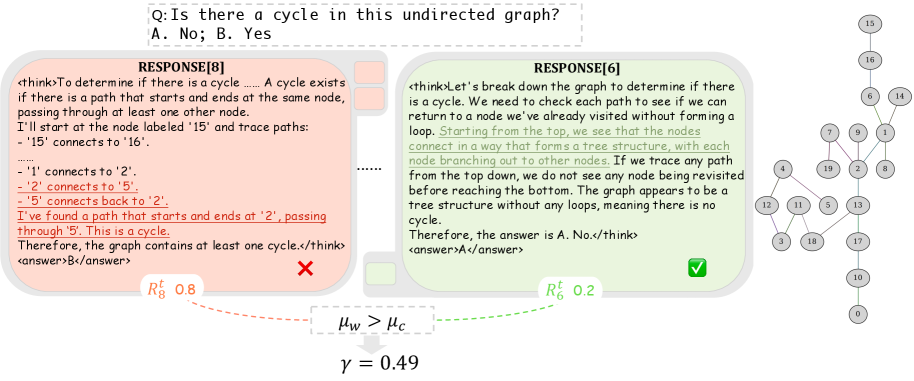
SophiaVL-R1 integrates a holistic thinking process reward into MLLM reinforcement learning, using a dynamic trustworthiness weight to discount unreliable process signals and prevent reward hacking.
Core Problem
Current RL methods for MLLMs rely on outcome rewards (did the model get the right answer?), which fail to penalize flawed reasoning processes that luckily guess the correct answer.
Why it matters:
- Models learn sub-optimal strategies (e.g., guessing) that do not generalize to harder problems
- Step-by-step Process Reward Models (PRMs) are computationally expensive and too rigid for general tasks
- Blindly adding process rewards leads to 'reward hacking' where models generate long but meaningless chains just to please the reward model
Concrete Example:
A model might correctly answer '2' to a visual math problem but use a thinking process that misidentifies the objects in the image. An outcome-only reward would reinforce this hallucination, while SophiaVL-R1's thinking reward would penalize the flawed logic despite the correct final answer.
Key Novelty
Trust-GRPO with Holistic Thinking Rewards
- Trains a Thinking Reward Model to score the *entire* reasoning process quality (holistic) rather than step-by-step, avoiding rigidity
- Calculates a 'trustworthiness weight' during training by comparing process rewards for correct vs. incorrect answers; if the reward model gives high scores to wrong answers, its influence is dynamically reduced
- Uses an annealing schedule to fade out the process reward over time, forcing the model to rely on the ground-truth outcome reward in later stages
Architecture
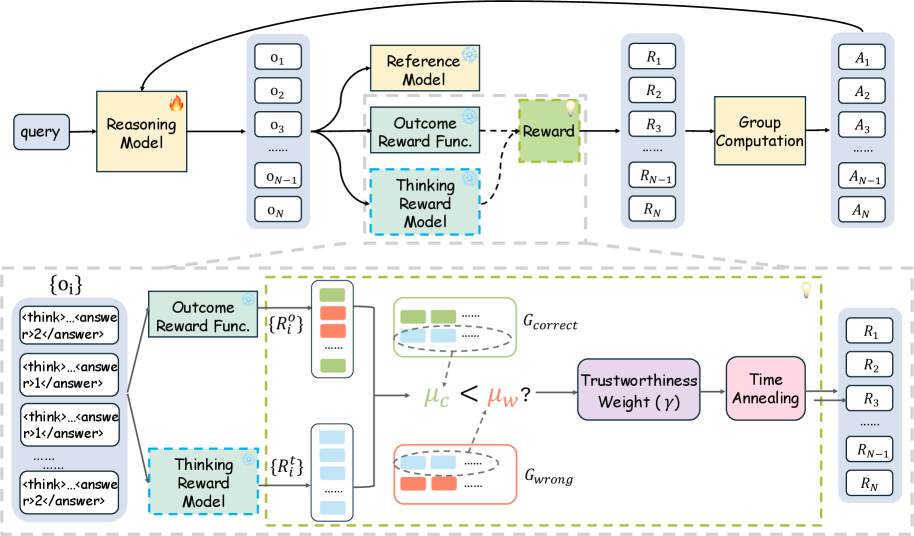
The Trust-GRPO training framework pipeline.
Evaluation Highlights
- SophiaVL-R1-7B achieves 71.3% on MathVista, outperforming the much larger LLaVA-OneVision-72B (68.4%)
- Outperforms VisualPRM-based method by 18.1 points on MathVerse (48.8 vs 30.7), showing superior process supervision
- Surpasses LLaVA-OneVision-72B on general multimodal benchmark MMMU (57.1 vs 52.6) despite having 10x fewer parameters
Breakthrough Assessment
8/10
Achieves SOTA performance on major MLLM benchmarks with a 7B model, significantly outperforming 72B baselines. The Trust-GRPO mechanism cleverly addresses the reliability issues of learned reward models.