📝 Paper Summary
Reinforcement Learning for Diffusion Models
Visual Generation Alignment
DiffusionNFT aligns diffusion models by defining an implicit policy improvement direction between positive and negative generations and optimizing the forward process via flow matching, avoiding complex reverse-process discretization.
Core Problem
Existing RL for diffusion models (like FlowGRPO) discretizes the reverse process to approximate likelihoods, which restricts solver choice, breaks forward-process consistency, and complicates integration with Classifier-Free Guidance (CFG).
Why it matters:
- Discretization forces the use of specific first-order SDE samplers, preventing the use of efficient high-order ODE solvers common in modern flow models.
- Focusing solely on the reverse process risks 'forward inconsistency,' where the model degenerates into cascaded Gaussians rather than a valid diffusion process.
- Current methods require training separate conditional and unconditional models to maintain CFG, doubling computational cost and complicating optimization.
Concrete Example:
FlowGRPO requires storing full sampling trajectories and using a specific SDE solver to estimate likelihoods. If a user wants to use a faster ODE solver (like Euler) for data collection, FlowGRPO cannot be directly applied because the deterministic path lacks the stochasticity needed for its policy gradient formulation.
Key Novelty
Forward-Process Negative-aware FineTuning
- Instead of treating generation as a multi-step decision process (RL view), it treats it as a supervised flow matching problem where the target velocity is shifted towards 'positive' samples and away from 'negative' ones.
- Defines an implicit 'reinforcement guidance' direction based on the difference between positive and negative policies, then distills this guidance directly into the model weights.
- Decouples data collection from training: allows sampling with any black-box solver (ODE or SDE) and requires storing only the final images and rewards, not the intermediate steps.
Architecture
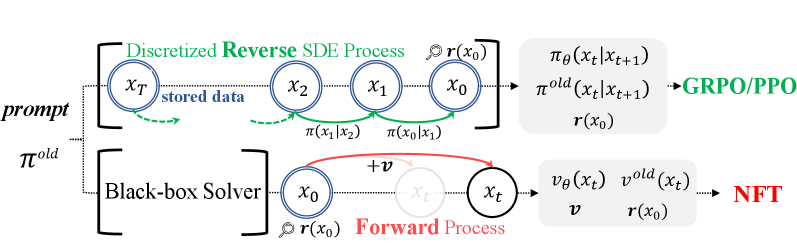
Comparison of DiffusionNFT vs. Policy Gradient (GRPO) pipelines. Shows DiffusionNFT optimizing the Forward Process using clean images + rewards, while GRPO optimizes the Reverse Process using full trajectories.
Evaluation Highlights
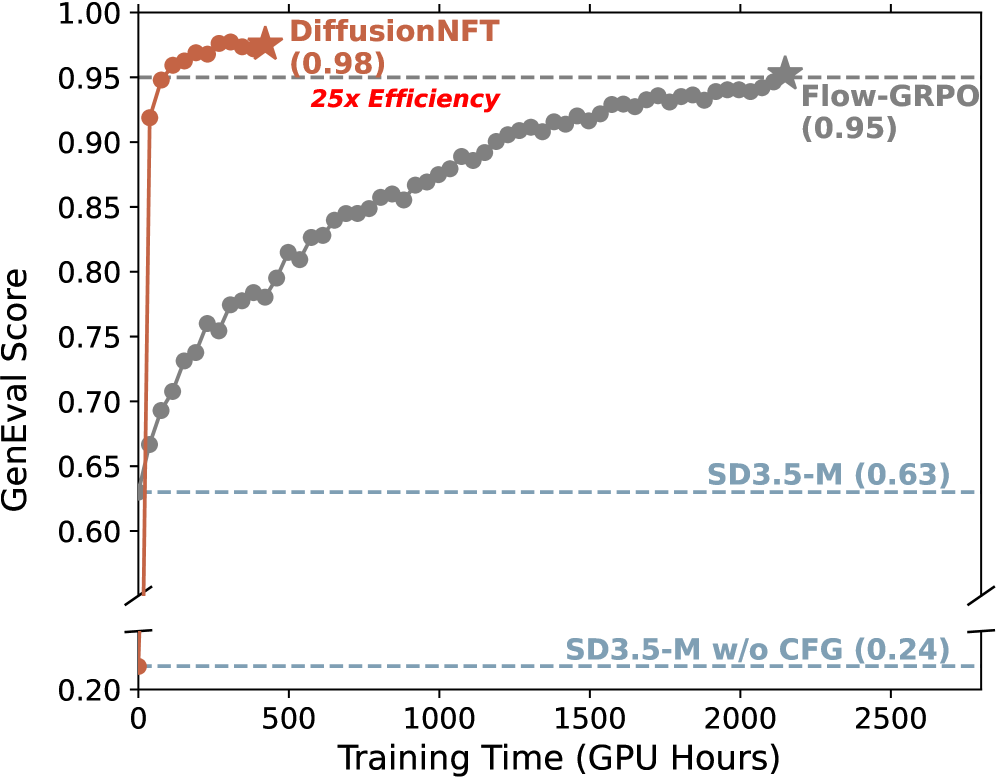
- Improves GenEval score from 0.24 to 0.98 within 1k steps, whereas FlowGRPO achieves 0.95 requiring over 5k steps and additional inference-time CFG.
- Achieves 3x to 25x greater training efficiency compared to FlowGRPO across four head-to-head tasks while reaching higher final rewards.
- Boosts SD3.5-Medium performance significantly on all benchmarks (PickScore, ImageReward, HPSv2) without using Classifier-Free Guidance (CFG) at inference.
Breakthrough Assessment
9/10
Offers a fundamental paradigm shift for Diffusion RL by moving from reverse-process likelihood estimation to forward-process flow matching. Solves major efficiency and compatibility bottlenecks (solver restrictions, CFG reliance) with impressive empirical gains.