📝 Paper Summary
Reinforcement Learning from Verifiable Rewards (RLVR)
Efficient Reasoning
Post-training Optimization
GFPO modifies Group Relative Policy Optimization by sampling more responses during training and filtering them based on length or token efficiency to produce concise reasoning chains without losing accuracy.
Core Problem
RL-trained reasoning models (like GRPO) tend to trade accuracy for excessive length—inflating response tokens significantly—even when shorter, correct reasoning paths exist.
Why it matters:
- Models like DeepSeek-R1 generate responses 5x longer than necessary, increasing inference costs and latency
- Length inflation is often uncorrelated with correctness; 'filler' tokens waste compute without improving reasoning quality
- Standard length penalties in reward functions often fail to curb this inflation because models learn that longer chains are generally safer for maximizing reward
Concrete Example:
On AIME 25, the GRPO baseline inflates response length from 10.9k tokens (SFT) to 14.8k tokens. GFPO reduces this back to 12k tokens (Token Efficiency variant) while maintaining accuracy, whereas GRPO rewards long, verbose chains even if they contain repetitive filler.
Key Novelty
Group Filtered Policy Optimization (GFPO)
- Combines rejection sampling with GRPO: sample a larger group of responses (G) but only train on the top-k subset that meets a specific criteria (e.g., shortest length)
- Acts as implicit reward shaping by zeroing out the advantages of rejected responses, effectively hiding verbose or inefficient chains from the policy update
- Introduces 'Token Efficiency' (reward/length) as a filtering metric to prioritize brevity only when it doesn't sacrifice reward
Architecture
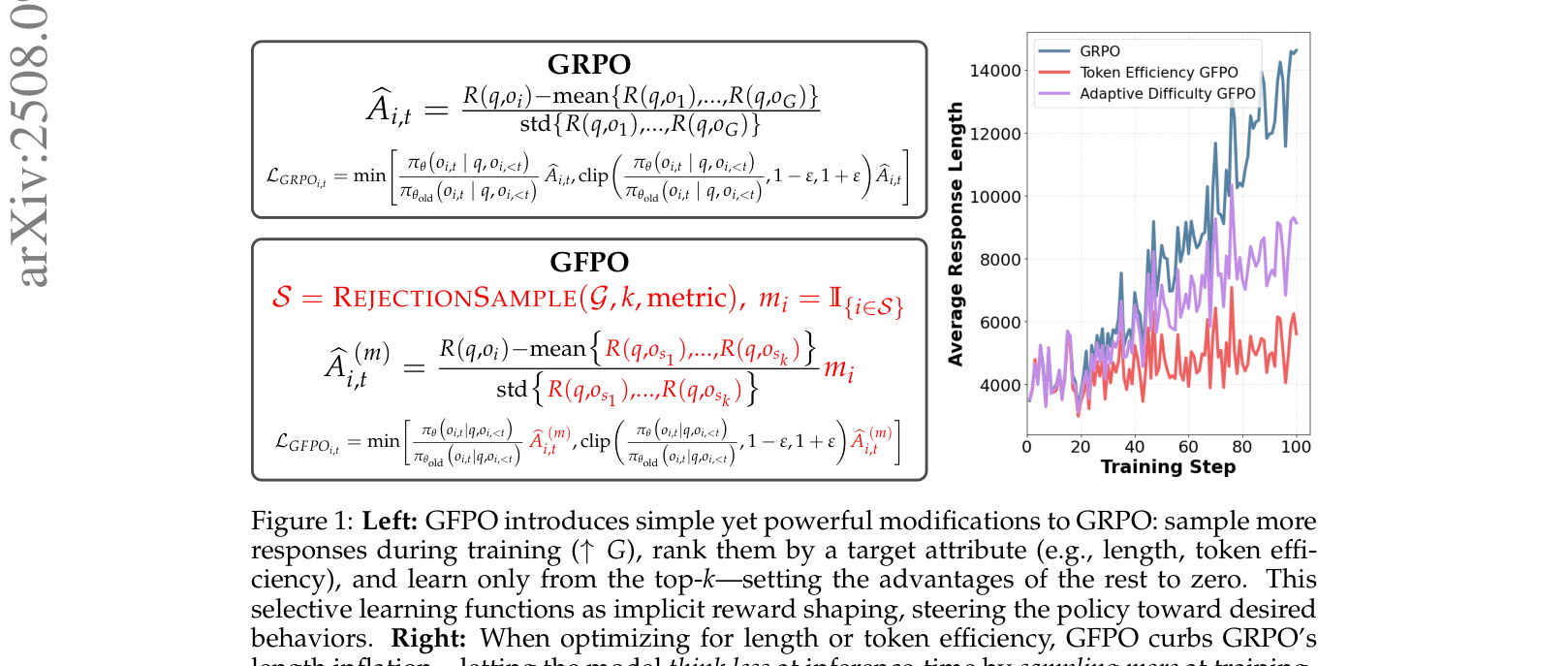
Conceptual comparison between GRPO and GFPO workflows. Shows how GFPO inserts a rejection sampling step before advantage calculation.
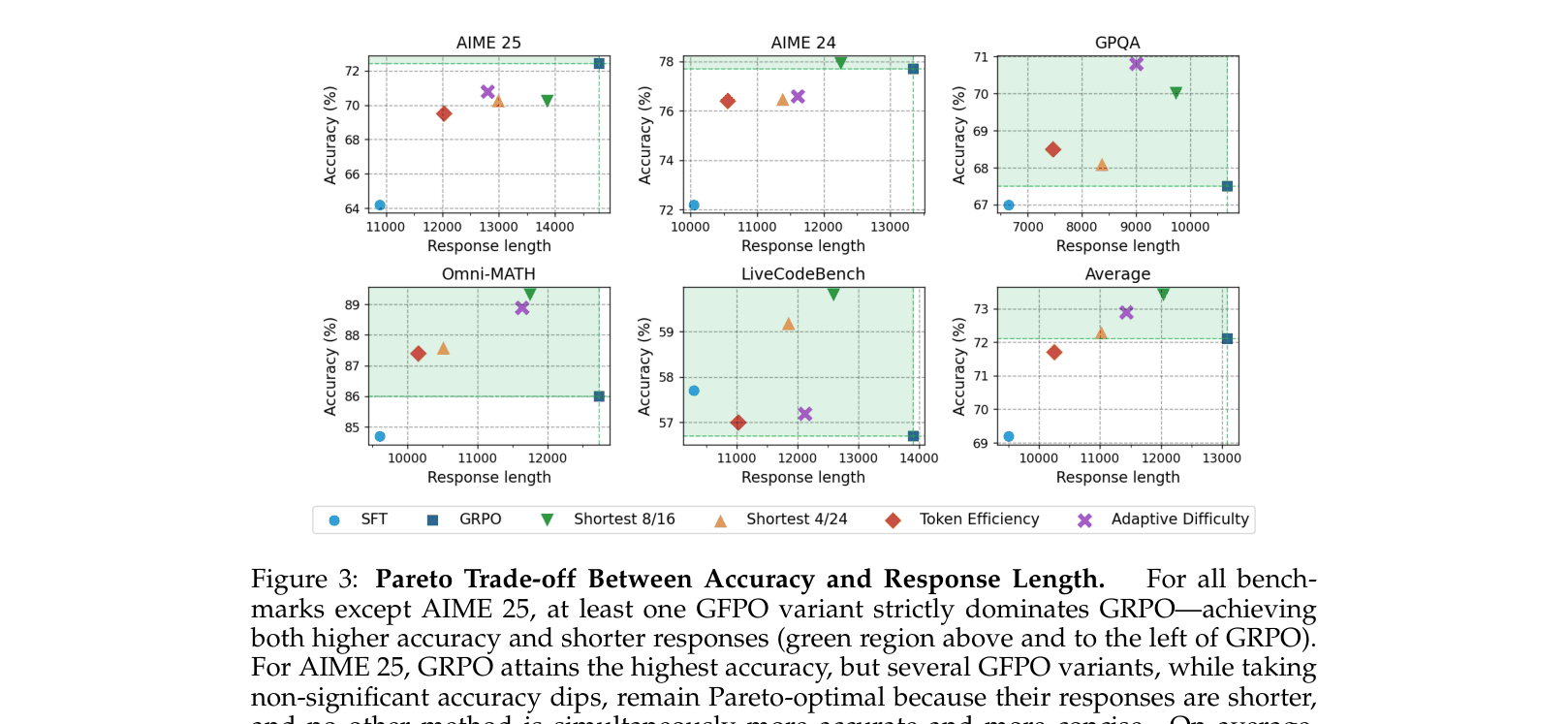
Evaluation Highlights
- Reduces length inflation by 70.9% on AIME 25 and 84.6% on AIME 24 using Token Efficiency GFPO compared to GRPO baseline
- Maintains statistical parity in accuracy with GRPO across 5 benchmarks (AIME 24/25, GPQA, Omni-MATH, LiveCodeBench) while using significantly fewer tokens
- Adaptive Difficulty GFPO matches or exceeds GRPO accuracy on medium and very hard problems while reducing excess length by 47–60%
Breakthrough Assessment
8/10
Simple yet highly effective intervention for a critical problem in current reasoning models (verbosity). Demonstrates a clear Pareto improvement in the accuracy-efficiency trade-off.