📝 Paper Summary
Multimodal Large Language Models (MLLMs)
Visual Perception and Reasoning
Ovis2.5 improves multimodal reasoning by integrating a native-resolution vision transformer to preserve fine details and a reflective 'thinking mode' trained via reinforcement learning to enable self-correction.
Core Problem
Current MLLMs struggle with dense visual content due to fixed-resolution tiling that breaks global structure, and lack deep reasoning capabilities because they are trained on linear paths without self-correction.
Why it matters:
- Fixed-resolution encoders necessitate image tiling, which compromises the global structure needed to interpret complex charts and diagrams.
- Training on linear Chain-of-Thought (CoT) lacks reflective supervision, preventing models from evaluating and refining their own intermediate reasoning steps.
Concrete Example:
When analyzing a complex chart, a standard model using fixed-resolution tiling might misinterpret the global layout or axis relationships because the image is split into arbitrary patches, whereas Ovis2.5 processes the full chart at its native aspect ratio.
Key Novelty
Native-Resolution Perception + Reflective Reasoning Mode
- Replaces fixed-size image tiling with NaViT (Native-resolution Vision Transformer), allowing the model to process images of varying aspect ratios directly to preserve layout and detail.
- Introduces a 'thinking mode' enabled by training on data with explicit reflection tags (<think>...</think>), allowing the model to trade latency for accuracy by verifying and correcting its own logic.
Architecture
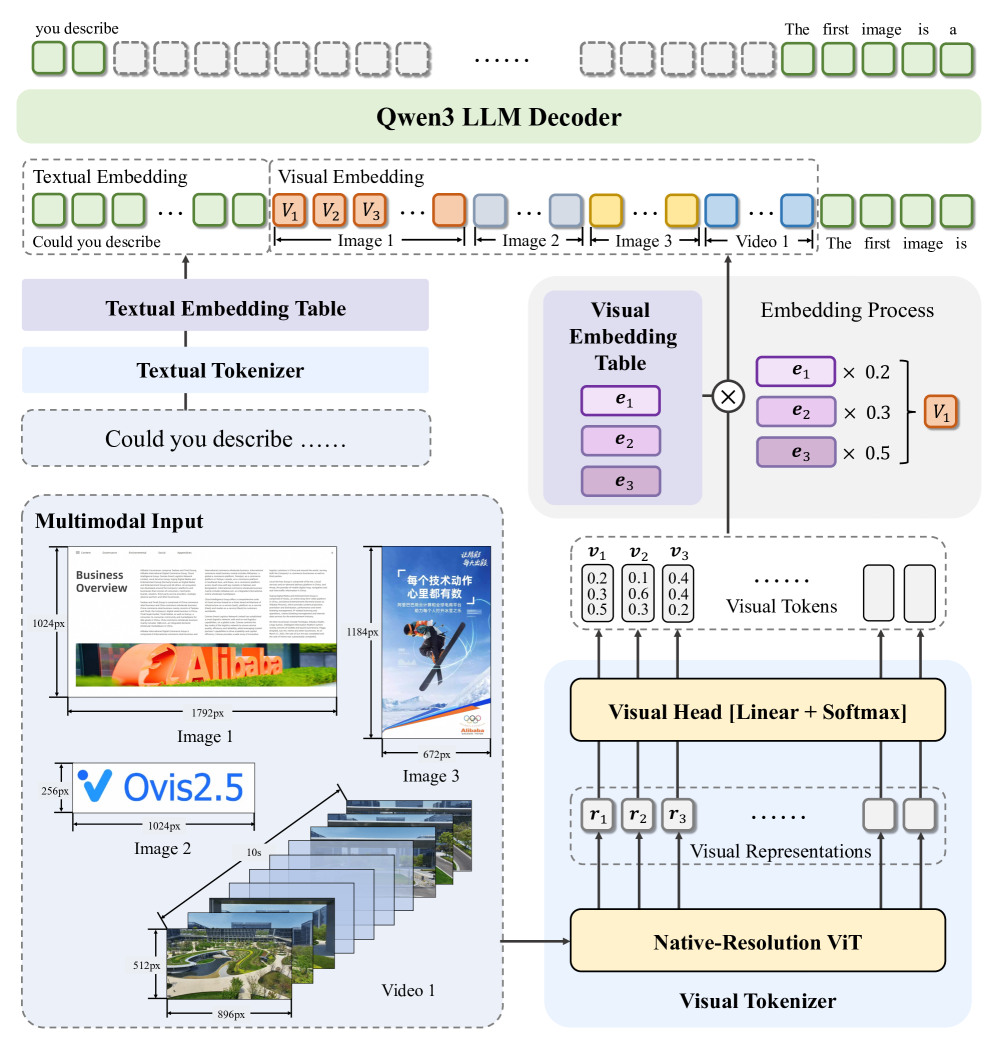
The overall architecture of Ovis2.5 showing the flow from native-resolution images to generated text.
Evaluation Highlights
- Ovis2.5-9B achieves an average score of 78.3 on the OpenCompass multimodal leaderboard, setting a new SOTA for open-source MLLMs under 40B parameters.
- Ovis2.5-2B achieves 73.9 on OpenCompass, establishing a state-of-the-art result among open-source MLLMs of comparable size.
- Achieves a 3–4x end-to-end training speedup via multimodal data packing and hybrid parallelism optimization.
Breakthrough Assessment
8/10
Significantly advances open-source MLLM capabilities by successfully combining native-resolution processing (solving tiling issues) with the 'System 2' reasoning paradigm (reflection) seen in recent LLMs like Qwen3.