📝 Paper Summary
Multimodal Reasoning
Visual Grounding
Reinforcement Learning for MLLMs
GRIT teaches multimodal models to interleave bounding box coordinates within textual reasoning chains using reinforcement learning and format-based rewards, requiring no human-annotated reasoning paths.
Core Problem
Current multimodal models generate reasoning chains in pure text, disconnected from specific image regions, and training grounded reasoning typically requires expensive, scarce datasets with step-by-step bounding box annotations.
Why it matters:
- Pure text reasoning in MLLMs (Multimodal Large Language Models) often hallucinates or fails to ground logic in visual evidence
- Existing solutions require dense, hard-to-obtain supervision (human annotations linking text steps to boxes)
- Models struggle to maintain context across multiple images if using pixel-level inputs for every step
Concrete Example:
When asking a complex visual question, a standard MLLM might say 'The man is holding a cup' without verifying the pixel region. GRIT produces '<think> The man [box_coords] is holding a cup [box_coords] </think>', forcing the model to explicitly locate the objects it references during the thought process.
Key Novelty
Grounded Reasoning with Images and Texts (GRIT)
- Defines a 'grounded reasoning paradigm' where the model outputs interleaved text and bounding box coordinates within reasoning tags (<think>...</think>)
- Uses a format-aware Reinforcement Learning algorithm (GRPO-GR) that rewards the *structure* of reasoning (presence of valid boxes and tags) and the *final answer*, rather than supervising the specific content of the intermediate steps
Architecture
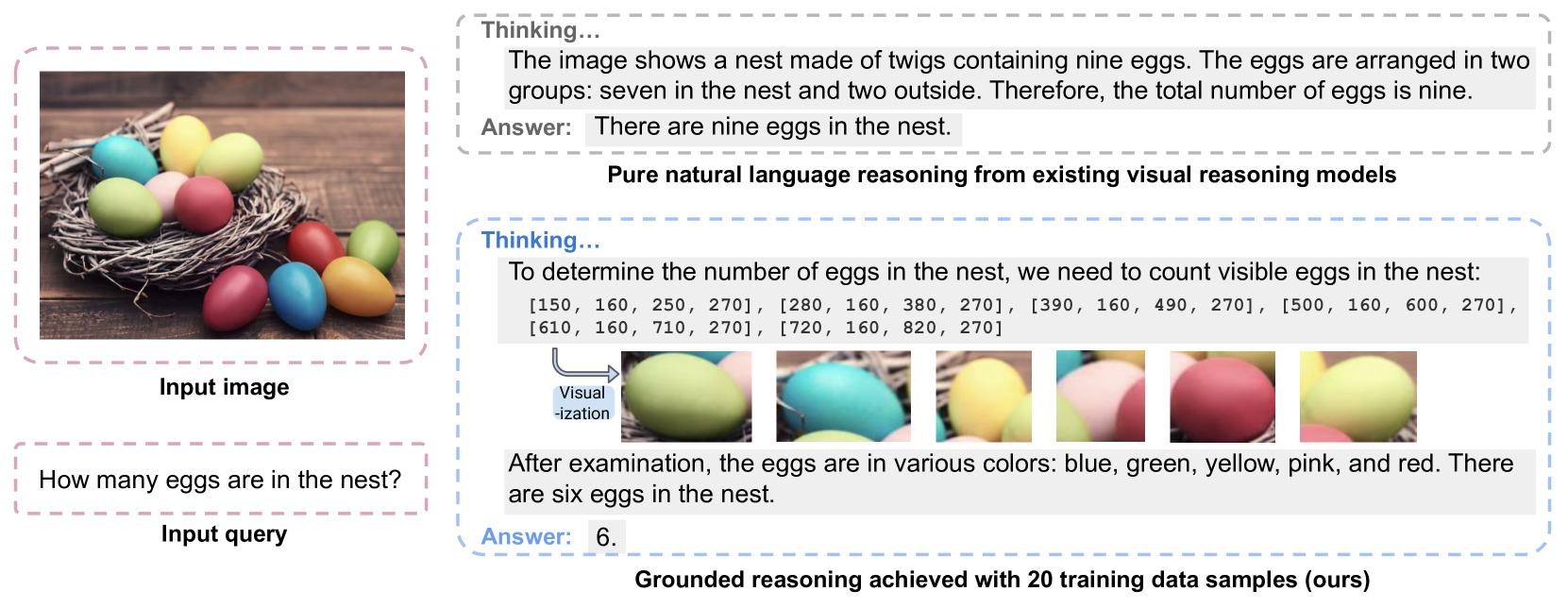
The Grounded Reasoning Paradigm. It illustrates how the model generates a reasoning chain that interleaves natural language with bounding box coordinates, followed by a final answer.
Evaluation Highlights
- Achieves grounded reasoning capability using only 20 image-question-answer triplets (from VSR and TallyQA datasets)
- Successfully trains state-of-the-art MLLMs (Qwen 2.5-VL and InternVL 3) to unify reasoning and grounding without dense supervision
Breakthrough Assessment
8/10
The method unlocks a complex capability (interleaved visual-textual thinking) with extreme data efficiency (20 samples) via pure RL, removing the bottleneck of expensive reasoning annotations.
