📝 Paper Summary
Text-to-Image Generation
Reinforcement Learning for Generative Models
Chain-of-Thought (CoT) Reasoning
T2I-R1 introduces a reinforcement learning framework that jointly optimizes two levels of reasoning—high-level semantic planning and low-level token generation—within a single Unified Large Multi-modal Model to improve text-to-image synthesis.
Core Problem
Standard text-to-image models generate images directly from prompts without explicit reasoning, struggling with complex instructions, ambiguous concepts, and fine-grained visual details.
Why it matters:
- Direct generation often fails to capture the true user intention when prompts are implicit or require deduction (e.g., 'flower of the country where Amsterdam is located').
- Separating planning (semantic understanding) from execution (pixel generation) is critical for complex scenes but rarely unified in a single optimized framework.
- Current approaches either rely on expensive external LLMs for prompt enhancement or lack the coordination between high-level understanding and low-level visual synthesis.
Concrete Example:
Given the prompt 'The flower cultivated in the country where Amsterdam is located', a standard model (Janus-Pro) fails to identify the flower. T2I-R1 first reasons 'Amsterdam is in the Netherlands... the flower is a tulip' (semantic-level CoT) before generating a correct image of a tulip.
Key Novelty
BiCoT-GRPO (Bi-level Chain-of-Thought Group Relative Policy Optimization)
- Decomposes image generation into two reasoning stages: 'Semantic-level CoT' (textual planning of scene/objects) and 'Token-level CoT' (step-by-step visual token generation).
- Optimizes both stages simultaneously using a single RL framework (GRPO) that treats the entire sequence (text reasoning + image tokens) as a unified chain of thought.
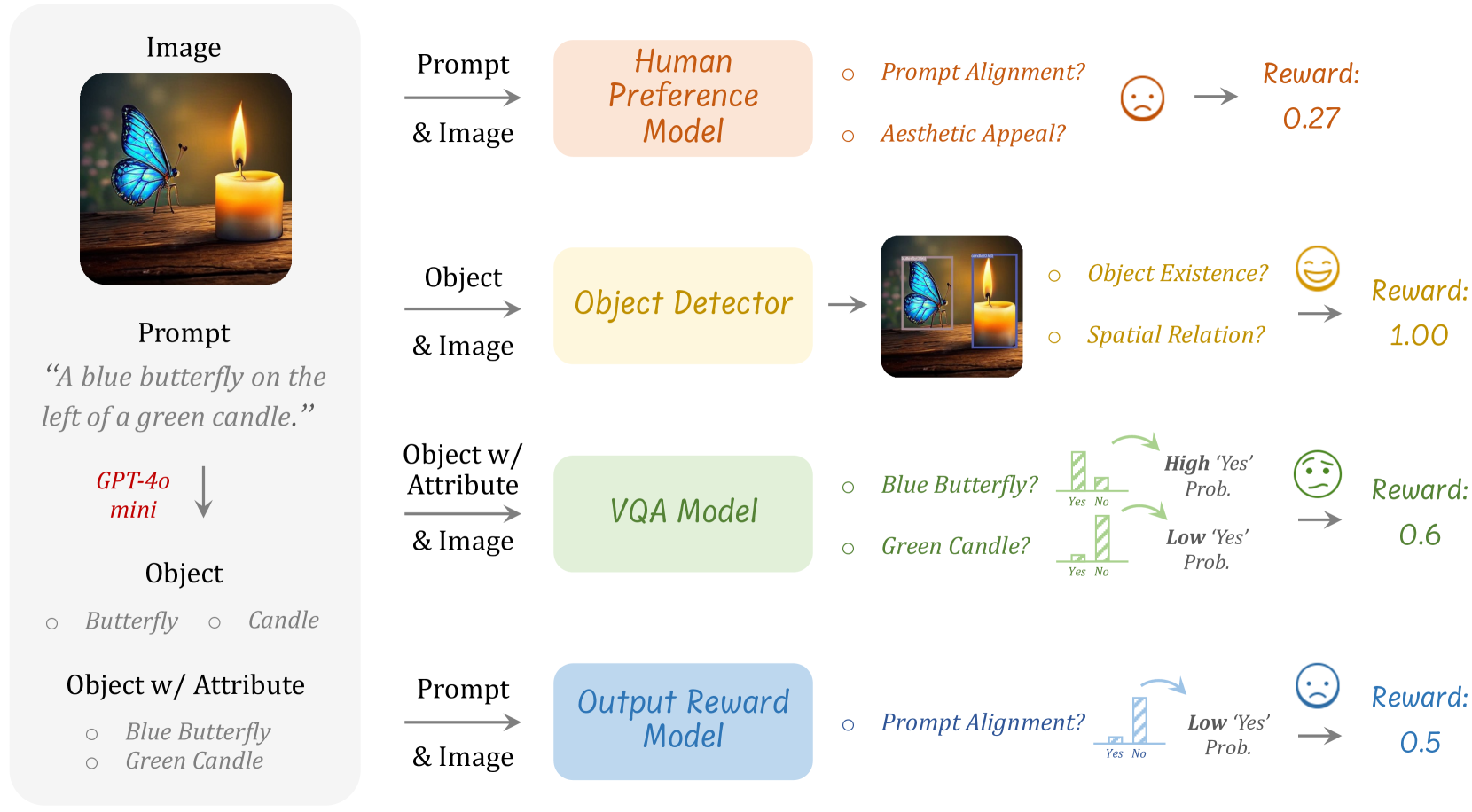
- Uses an ensemble of vision experts (Human Preference Models, Object Detectors, VQA) as the reward signal to guide the model's self-exploration without requiring ground-truth images.
Architecture
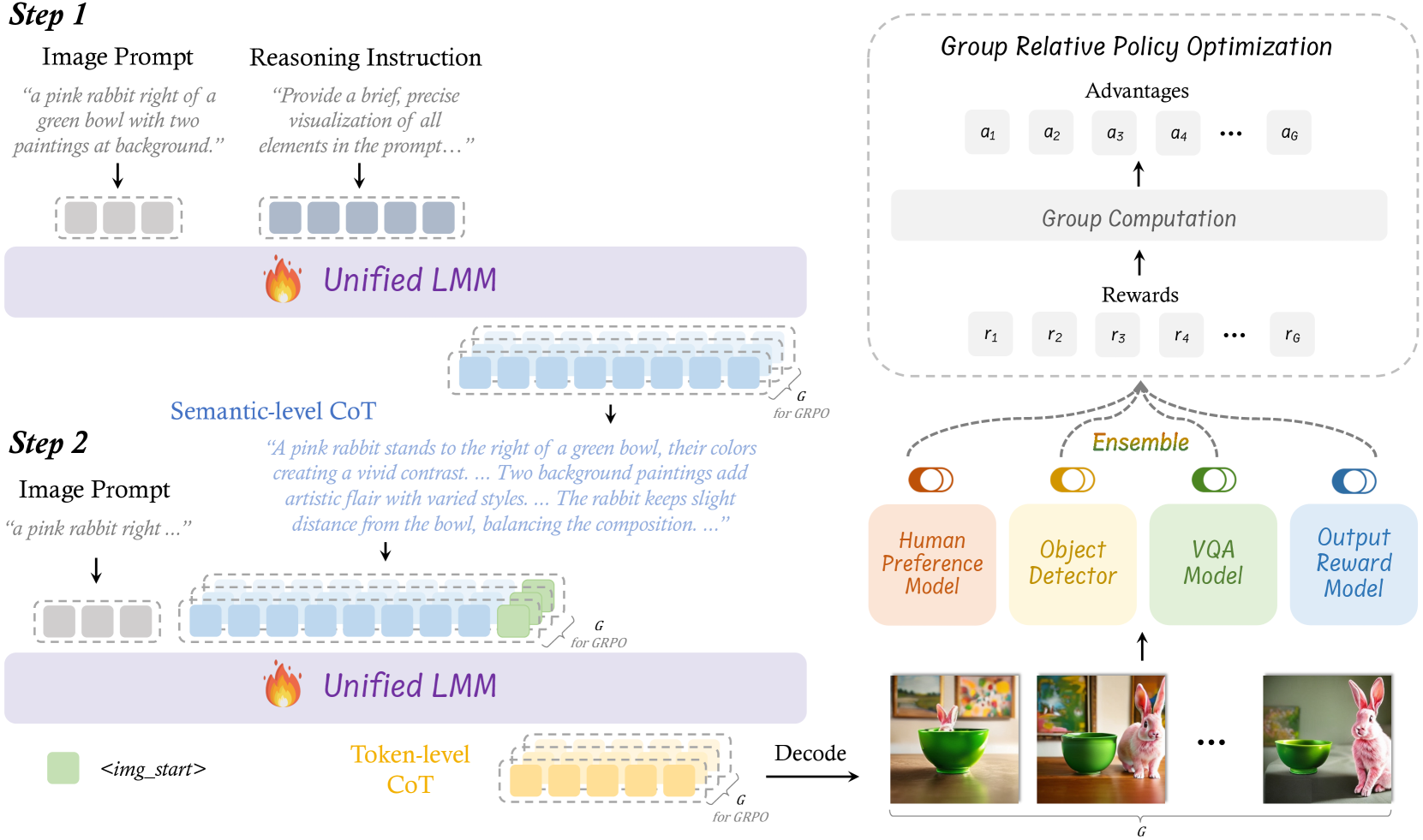
The BiCoT-GRPO training pipeline showing the two-stage generation process and the ensemble reward calculation.
Evaluation Highlights
- +13% improvement on T2I-CompBench compared to the Janus-Pro baseline.
- +19% improvement on the WISE benchmark compared to the Janus-Pro baseline.
- Surpasses the state-of-the-art model FLUX.1 on multiple benchmarks despite being a smaller Unified Large Multi-modal Model.
Breakthrough Assessment
8/10
Significantly advances autoregressive image generation by successfully integrating reasoning (CoT) directly into the visual generation process via RL, showing that 'thinking before drawing' works for pixels.