📊 Experiments & Results
Evaluation Setup
RL fine-tuning of a cold-start MoE model on math and code tasks
Benchmarks:
- AIME'24 (Mathematics)
- LiveCodeBench (Code Generation)
- CodeForces (Competitive Programming)
Metrics:
- Pass@1 (average over samplings)
- Elo Rating
- Statistical methodology: Not explicitly reported in the paper
Experiment Figures
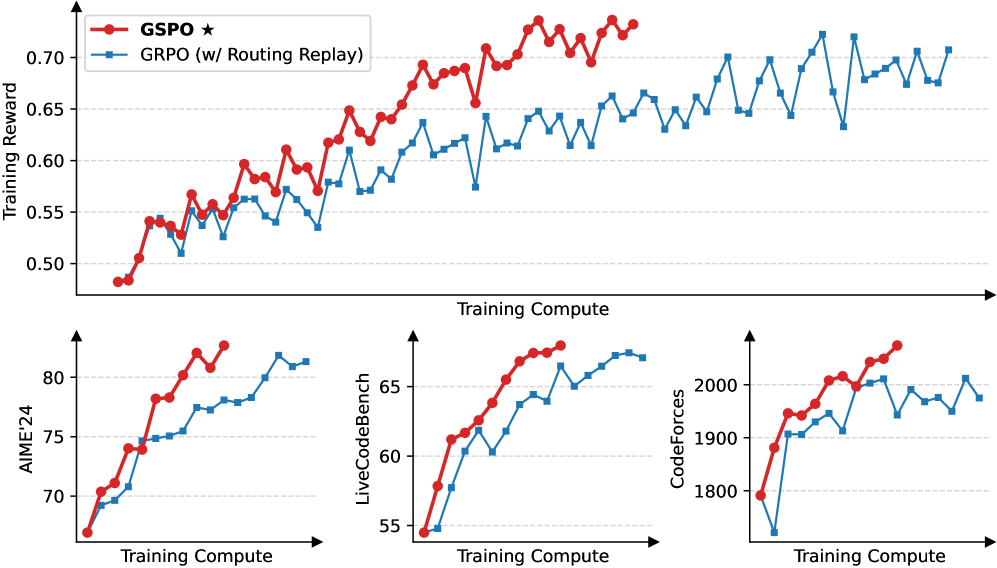
Comparison of training stability and performance between GSPO and GRPO.
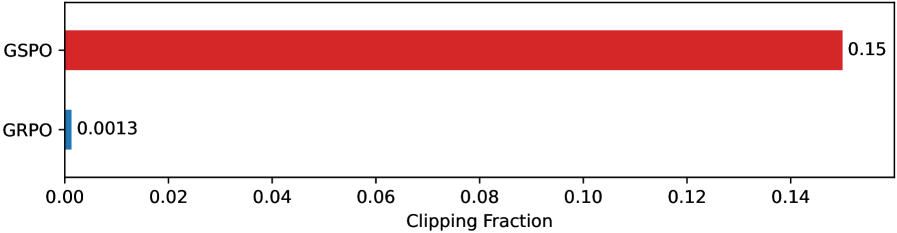
Fractions of clipped tokens/samples in GSPO vs GRPO.
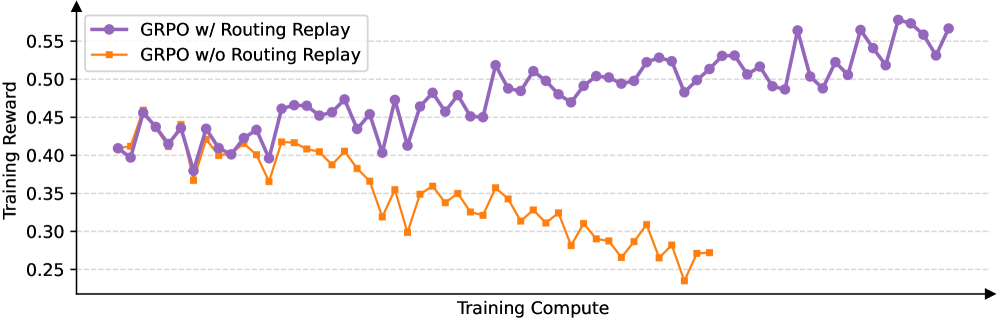
Impact of Routing Replay on GRPO stability.
Main Takeaways
- GSPO achieves stable training dynamics where GRPO fails or requires 'Routing Replay' for MoE models.
- GSPO allows for continuous performance improvement with increased compute and generation length, unlike GRPO which faces collapse.
- GSPO is robust to precision discrepancies between training and inference engines, enabling disaggregated frameworks.
- Clipping a larger fraction of tokens (via sequence clipping) paradoxically leads to better efficiency, suggesting token-level gradients in GRPO are noisy.
- Eliminates the need for Routing Replay, reducing memory/communication overhead for MoE training.