📝 Paper Summary
LLM Post-training
Reinforcement Learning for Reasoning
Large Language Model Analysis
R1-Zero-like training relies on base models that already possess reasoning capabilities and requires correcting an optimization bias in GRPO that artificially promotes long, incorrect responses.
Core Problem
Replicating R1-Zero is challenging due to misconceptions about base model capabilities (e.g., 'Aha moments' are assumed to be purely RL-emergent) and optimization biases in the popular GRPO algorithm.
Why it matters:
- The 'scaling of test-time compute' via reinforcement learning is a key frontier in LLM reasoning, but the mechanisms are poorly understood
- The standard GRPO algorithm introduces a length bias that causes models to generate progressively longer incorrect responses (overthinking) without improving accuracy
- Misinterpreting base model capabilities leads to incorrect attribution of performance gains to RL rather than pretraining
Concrete Example:
When training with standard GRPO, a model's incorrect responses grow longer because the loss function divides by length, penalizing long incorrect answers less than short ones. Dr. GRPO removes this bias, stopping the 'wild' growth of incorrect reasoning chains.
Key Novelty
Dr. GRPO (GRPO Done Right) and Critical Base Model Analysis
- Identifies that the standard GRPO objective effectively penalizes long incorrect responses less than short ones (due to length normalization), creating an artificial incentive for verbose failures
- Proposes Dr. GRPO, which removes length and standard deviation normalization terms to recover an unbiased PPO-like objective while maintaining memory efficiency
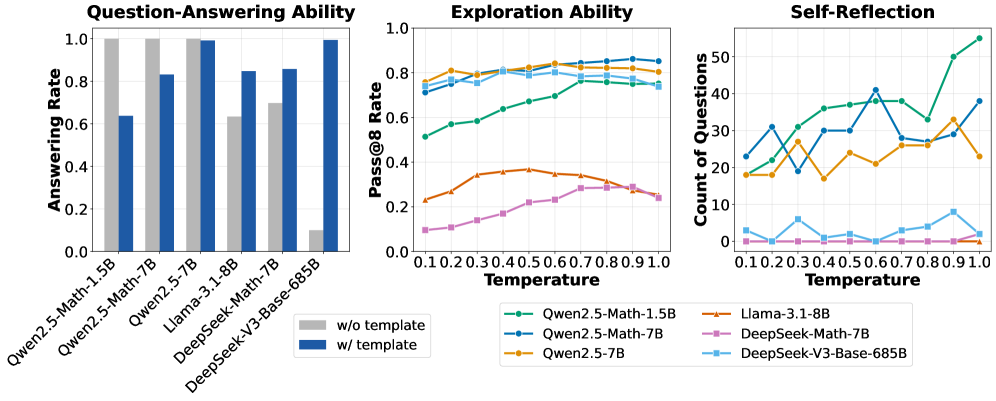
- Demonstrates that 'Aha moments' (self-correction) and strong reasoning are already present in base models like DeepSeek-V3-Base and Qwen2.5-Math, contradicting the belief they emerge solely from RL
Architecture

Illustration of the Optimization Bias in GRPO vs. Unbiased Objective
Evaluation Highlights
- Achieves 43.3% accuracy on AIME 2024 with a 7B model (Qwen2.5-Math-7B) using the proposed minimalist recipe, establishing a new state-of-the-art for this size
- Removing prompt templates improves Qwen2.5-Math-7B performance by +30.5 points (average across 5 benchmarks) compared to 4-shot prompting, suggesting SFT-like pretraining
- Dr. GRPO significantly improves token efficiency compared to vanilla GRPO, preventing the explosion of response length for incorrect outputs while maintaining accuracy
Breakthrough Assessment
8/10
Provides critical, demystifying insights into R1-Zero replication. Identifies a fundamental flaw in a widely used algorithm (GRPO) and offers a simpler, unbiased fix (Dr. GRPO) yielding SOTA results.