📝 Paper Summary
Flow Matching
Reinforcement Learning for Generative Models
TP-GRPO improves text-to-image alignment by replacing sparse outcome-based rewards with dense step-wise incremental rewards and explicitly modeling 'turning point' steps that steer trajectories toward better long-term outcomes.
Core Problem
Existing Flow-GRPO methods assign the final image's reward to every preceding denoising step identically, ignoring individual step contributions and creating sparse, misaligned feedback signals.
Why it matters:
- Outcome-based rewards cannot distinguish between beneficial and harmful steps within a trajectory, leading to inefficient policy optimization
- Current methods ranking whole trajectories ignore 'implicit interactions' where early steps (turning points) critically influence future reward evolution despite local metric fluctuations
- Uniform reward assignment reinforces steps that might locally degrade quality just because the final outcome happened to be good
Concrete Example:
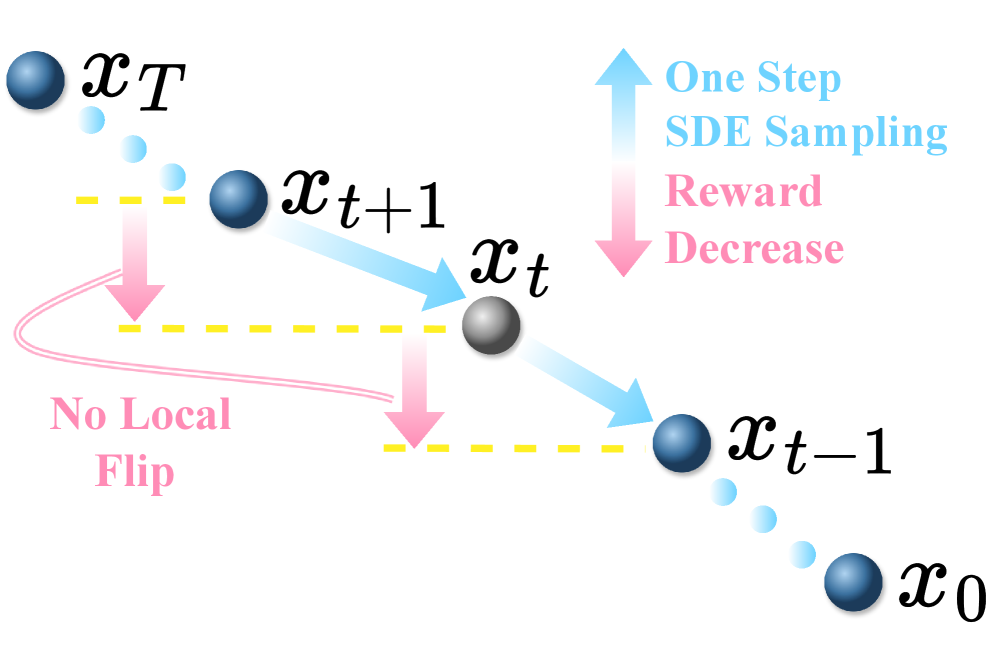
In a denoising trajectory, a specific step might decrease the estimated image quality locally (a dip in reward), but this step is necessary to steer the generation toward a high-quality final image. Standard Flow-GRPO assigns the high final reward to this dipping step, incorrectly reinforcing the local degradation, or conversely, penalizes a crucial turning point if the overall trajectory is mediocre.
Key Novelty
TurningPoint-GRPO (TP-GRPO)
- Replaces sparse terminal rewards with 'incremental rewards' calculated by differencing the value of ODE-completed images before and after each stochastic step, isolating the specific gain of that action
- Identifies 'turning points'—steps where the local reward trend flips to align with the global trajectory trend—and assigns them an aggregated long-term reward to capture their delayed impact on the final generation
Architecture
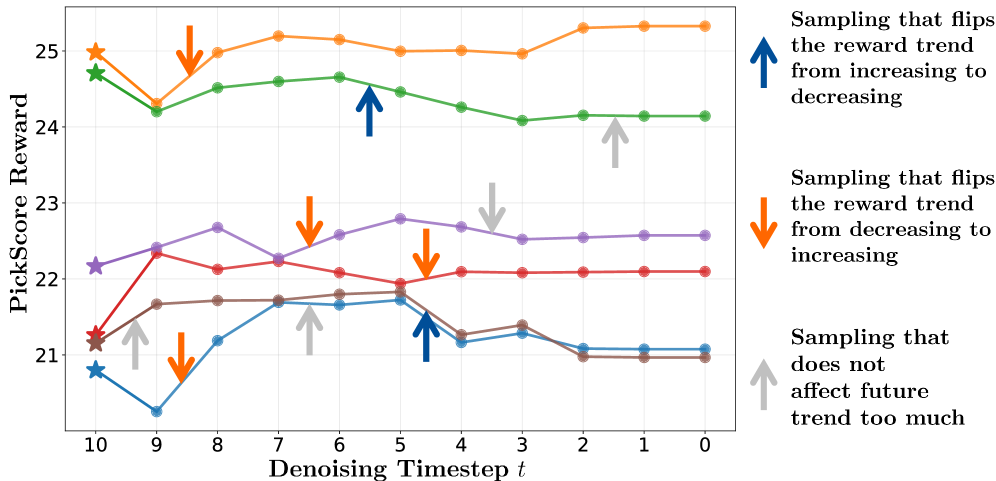
Comparison of reward assignment strategies. It shows SDE sampling trajectories where intermediate rewards (estimated via ODE) oscillate.
Breakthrough Assessment
7/10
Addresses a fundamental limitation in RL for flow models (reward sparsity) with a theoretically grounded approach (ODE completion for step-wise credit), though validation is limited to the method's logic in the provided text.