📝 Paper Summary
Multimodal Large Language Models (MLLMs)
Reinforcement Learning for MLLMs
AI-Generated Content (AIGC) Evaluation
HCM-GRPO enhances small Multimodal LLMs' ability to critique AI-generated images by combining a new aesthetic reasoning dataset with a reinforcement learning strategy that prioritizes hard examples and partial-credit rewards.
Core Problem
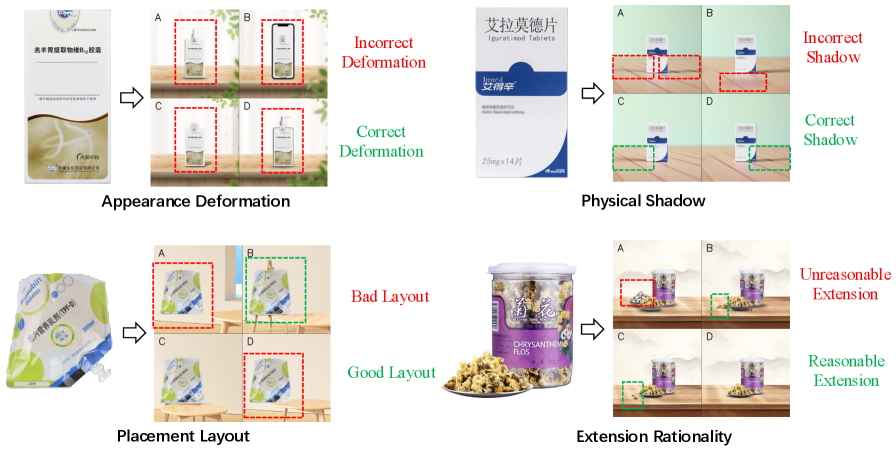
Current Multimodal LLMs lack the ability to effectively screen AI-generated images for aesthetic and logical flaws (e.g., deformation, bad shadows), performing near random guessing on such tasks.
Why it matters:
- Diffusion models frequently produce artifacts (unintended content, physical inconsistencies) that require automated filtering, but manual screening is unscalable.
- Existing MLLMs struggle with fine-grained visual reasoning and spatial understanding required to detect these subtle generation errors.
- Large-scale open-source and closed-source models (like GPT-4o) fail to reliably identify these issues, necessitating specialized training methods.
Concrete Example:
When checking a generated image of a medicine bottle for 'physical shadow' errors, a standard MLLM might accept an image where objects cast shadows in conflicting directions. The proposed model correctly identifies this as a flaw by reasoning about light sources.
Key Novelty
Hard Cases Mining in Group Relative Policy Optimization (HCM-GRPO)
- Introduces a 'Dynamic Proportional Accuracy' (DPA) reward that gives partial credit for partially correct multiple-choice answers, providing denser feedback than binary rewards.
- Implements a 'Hard Cases Mining' strategy where the model first identifies difficult samples (those it gets wrong) and then oversamples them in later training stages to focus learning on weaknesses.
- Constructs a comprehensive dataset (128k samples) specifically for detecting generation errors like appearance deformation and physical inconsistency.
Architecture
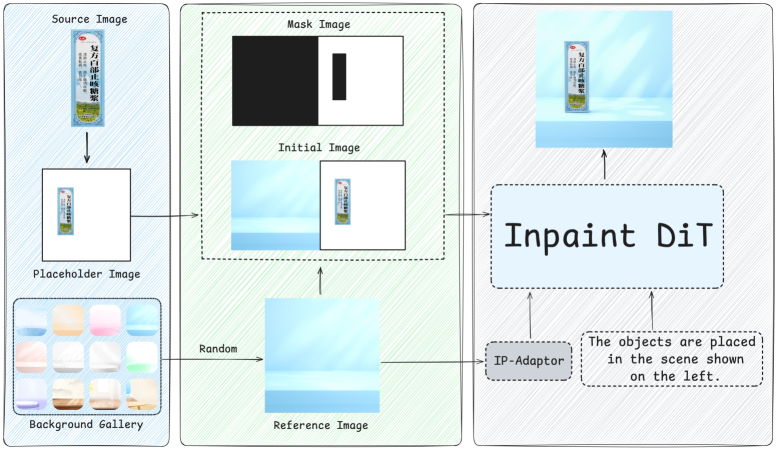
The training pipeline including Stage 1 (SFT) and Stage 2 (HCM-GRPO).
Evaluation Highlights
- +20 points improvement by the small model (InternVL3-2B with HCM-GRPO) over large-scale open-source and closed-source models (including GPT-4o) on the proposed aesthetic reasoning benchmark.
- Achieves a score of 64.74 on the evaluation dataset using a 2B parameter model, surpassing larger baselines that perform near random guessing.
- Demonstrates applicability to real-world and multi-image understanding tasks beyond the specific training domain.
Breakthrough Assessment
7/10
Significant performance jump for small models on a specific, useful task (image screening). The dataset and RL methodology are sound, though the scope is specialized to aesthetic reasoning.