📝 Paper Summary
Remote Sensing (RS) Analysis
Multimodal Small Language Models (MSLMs)
Reinforcement Learning for Reasoning
SAMChat adapts a small multimodal model for identifying missile sites by distilling reasoning from larger models and refining accuracy via reinforcement learning on a custom remote sensing dataset.
Core Problem
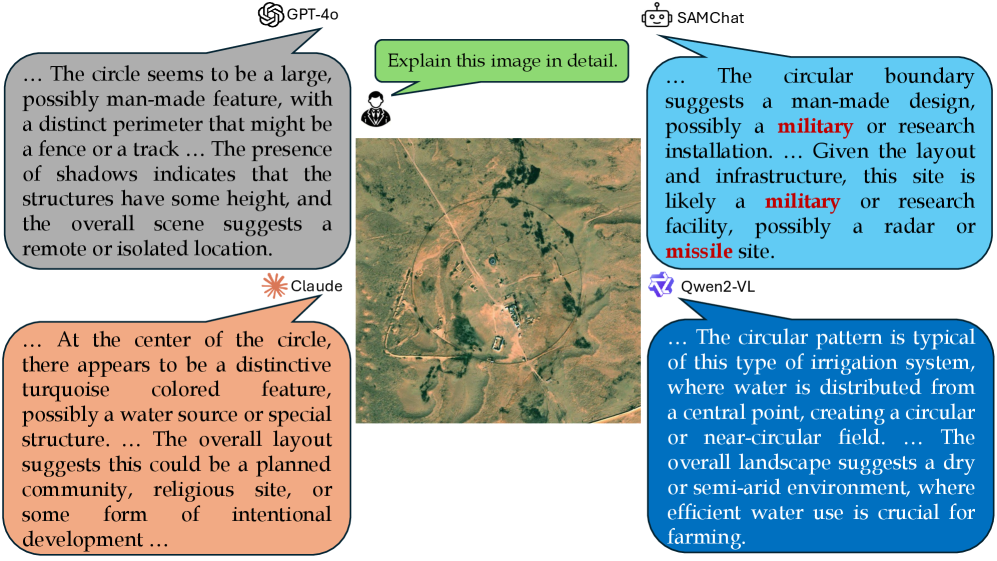
Generalist multimodal models and existing remote sensing models struggle with open-ended interpretation of secluded military sites, often failing to distinguish subtle missile installations from civilian infrastructure.
Why it matters:
- Large generalist models have high computational demands unsuitable for resource-constrained edge deployment in remote areas
- Existing RS-specific models focus on prompt-guided tasks (e.g., specific detection) rather than open-ended explanation, limiting their utility for complex scene understanding
- Accurate identification of missile sites requires distinguishing fine-grained details (e.g., circular pads vs. civilian structures) to avoid dangerous false positives
Concrete Example:
When analyzing aerial imagery of a secluded area, a standard model might miss a subtle surface-to-air missile (SAM) site or misclassify a civilian farm as military. SAMChat aims to correctly identify the 'classic circular layout of missile launch pads' or 'restricted perimeters' while rejecting look-alike civilian structures.
Key Novelty
SAMChat-R1 (Reinforcement Learning-adapted Remote Sensing MSLM)
- Distills complex reasoning patterns from a large model (GPT-4o) into a small 2B-parameter model via Supervised Fine-Tuning (SFT) on detailed Chain-of-Thought captions
- Applies Group Relative Policy Optimization (GRPO) with a keyword-based reward function to reinforce correct military identification while penalizing false positives on civilian imagery
Architecture
The SAMChat model architecture based on Qwen2-VL-2B
Evaluation Highlights
- Achieved over 80% Recall and 98% Precision on the SAMData test set for classifying missile sites
- Outperforms larger generalist models (Qwen2-VL-7B) and RS-specific baselines (GeoChat, RS-LLaVA) on keyword-based classification metrics
- Successfully identifies military sites in hard examples (Category 1) where the teacher model (Qwen2-VL-72B) originally failed
Breakthrough Assessment
7/10
Significant for demonstrating that RL (GRPO) and CoT can make small (2B) models outperform larger ones in niche domains like remote sensing. Limited by the small scale of the dataset (300 images).