📝 Paper Summary
Reinforcement Learning for MLLMs
Synthetic Data Generation
Syn-GRPO overcomes data quality bottlenecks in MLLM perception training by coupling an online image synthesis server with a GRPO workflow that rewards response diversity.
Core Problem
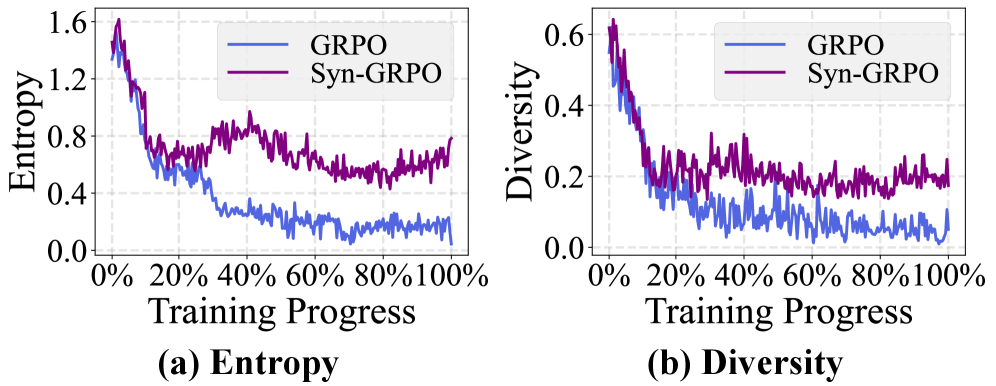
Existing RL methods for MLLM perception suffer from low data quality, where static training samples fail to elicit diverse responses, leading to entropy and diversity collapse during training.
Why it matters:
- Low data diversity restricts the exploration scope of reinforcement learning, causing the model to converge prematurely to narrow solutions
- Visual perception tasks have inherent verifiable labels but often lack the complexity needed to drive deep reasoning chains in MLLMs
- Standard entropy regularization techniques (like clipping) mitigate symptoms but do not address the root cause of insufficient data variety
Concrete Example:
In visual reasoning, a standard image might always yield simple, uniform descriptions from the model. Without variation, the RL agent quickly learns a fixed pattern (collapsing entropy) rather than exploring better reasoning paths, limiting performance gains.
Key Novelty
Self-Evolving Data Synthesis (Syn-GRPO)
- Integrates an asynchronous data server that generates new training images on-the-fly by modifying backgrounds while preserving foreground objects (labels)
- Introduces a diversity reward that encourages the MLLM to predict image descriptions that will yield diverse future responses, rather than just accurate ones
- Uses a diversity smoothing mechanism to calibrate rewards against the model's evolving diversity baseline, preventing distribution drift during training
Architecture
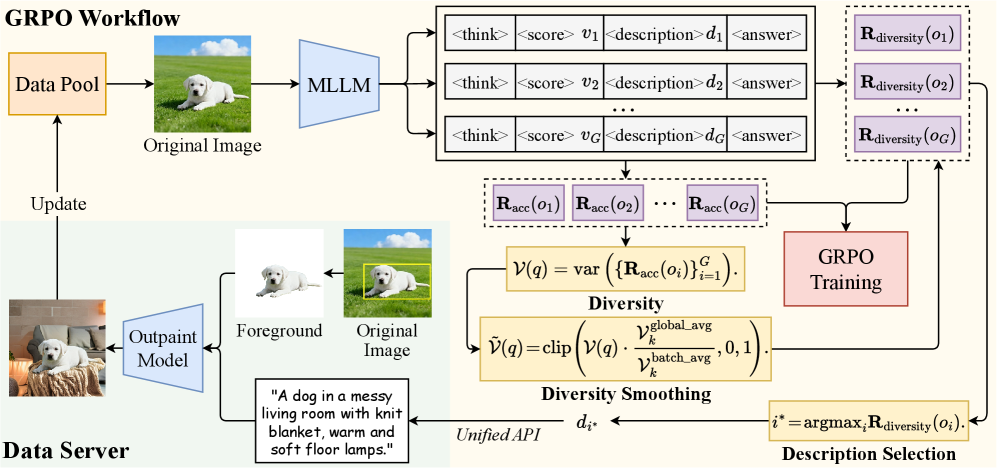
The overall framework of Syn-GRPO, illustrating the interaction between the Data Server and the GRPO Workflow.
Evaluation Highlights
- Outperforms Visual-RFT by +3.4% accuracy on RefCOCOg (REC task) using Qwen2-VL-2B
- Achieves +3.9% mAP improvement over Visual-RFT on OVD task (COCO2017) with Qwen2-VL-2B
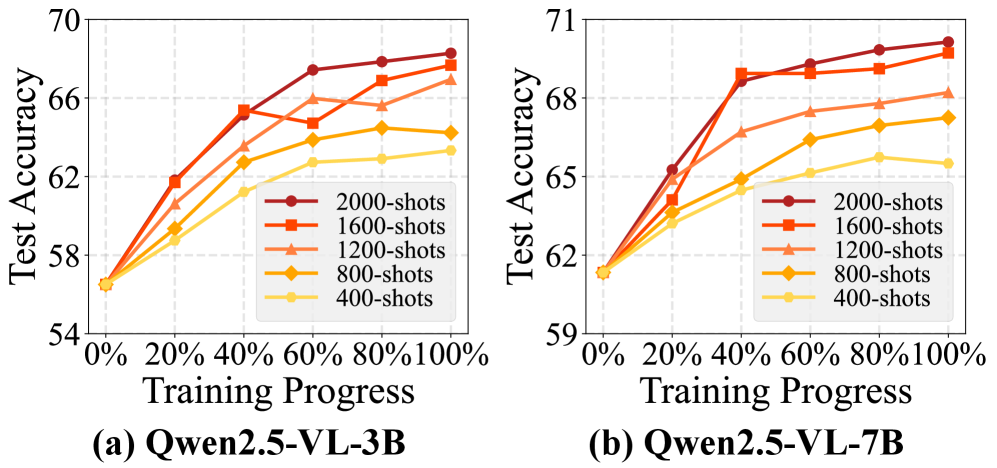
- Demonstrates sustained performance gains as dataset size increases, unlike baselines that plateau
Breakthrough Assessment
8/10
Significantly addresses the 'data wall' in RL for MLLMs by closing the loop between reasoning and data generation. The decoupling of synthesis and training is a strong engineering contribution.