📝 Paper Summary
Aerial Vision-Language Models
Visual Question Answering (VQA)
Reinforcement Learning for VLMs
UAV-VL-R1 adapts lightweight vision-language models to aerial imagery by combining supervised fine-tuning with multi-stage Group Relative Policy Optimization (GRPO) to enforce structured, interpretable reasoning chains.
Core Problem
General-purpose vision-language models degrade on UAV imagery due to unique bird's-eye perspectives, high resolution, and complex spatial semantics, often producing unexplainable or hallucinated outputs.
Why it matters:
- UAV applications like disaster monitoring require real-time, robust reasoning that general models cannot provide due to domain gaps
- Standard Supervised Fine-Tuning (SFT) encourages pattern memorization rather than true spatial reasoning, failing in structured tasks like counting or location inference
- Existing aerial datasets lack the reasoning annotations needed to train interpretable 'Chain-of-Thought' capabilities
Concrete Example:
In an aerial image, a standard VLM might correctly identify a car but fail to count vehicles in a crowded intersection or explain their spatial relationships, whereas UAV-VL-R1 produces a structured trace (<think>...</think>) detailing the counting process before answering.
Key Novelty
Hybrid SFT + Multi-Stage GRPO Curriculum
- Combines SFT for initial semantic alignment with a three-stage reinforcement learning curriculum (Attributes → Objects → Spatial relations) to progressively build reasoning complexity
- Utilizes Group Relative Policy Optimization (GRPO) to estimate advantages from group-wise output comparisons, eliminating the need for a separate value function model
- Enforces a dual-tag output format (<think> for reasoning, <answer> for result) via rule-based rewards to ensure interpretability
Architecture
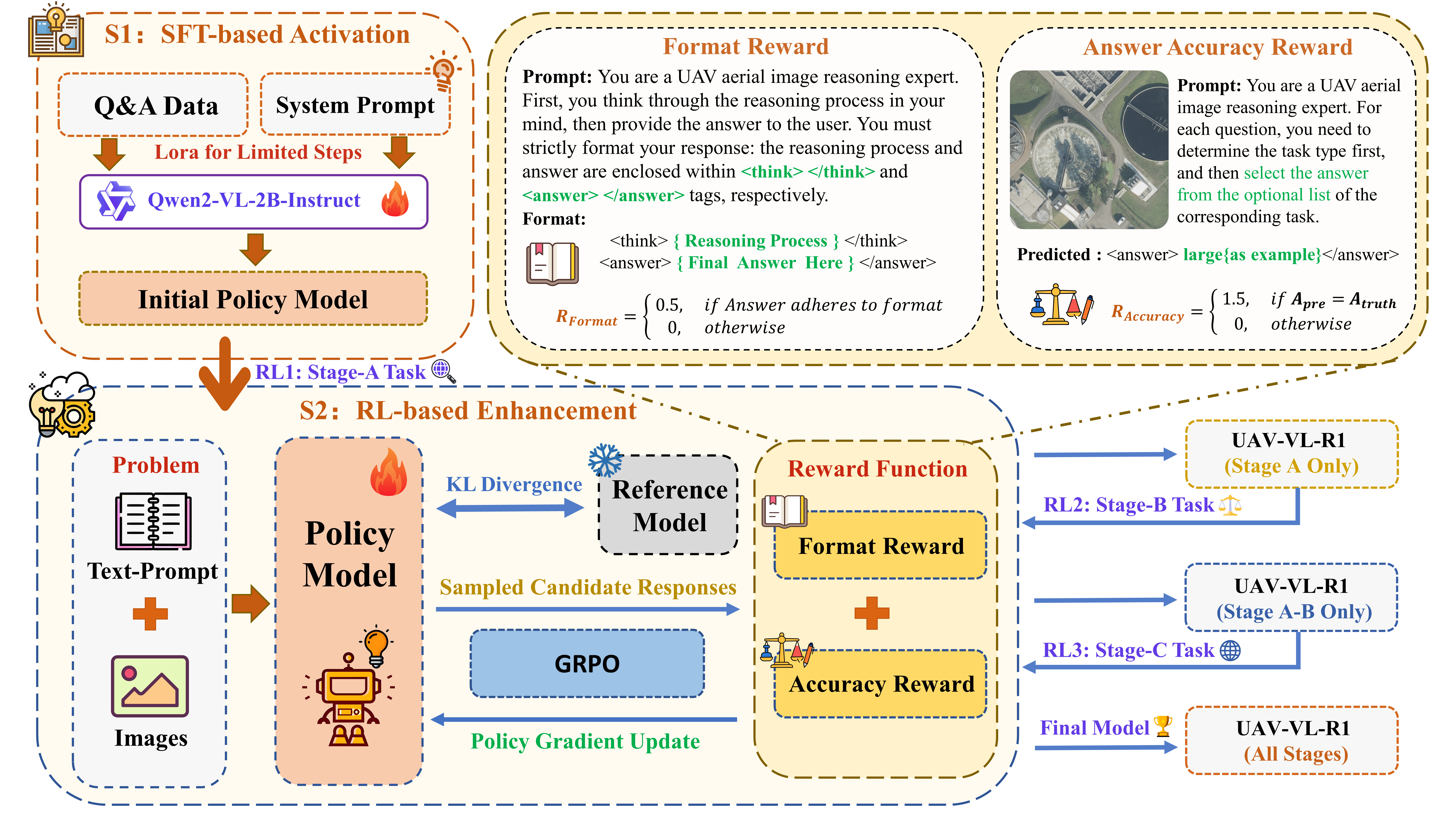
The training pipeline comprising SFT initialization and three-stage GRPO reinforcement learning.
Evaluation Highlights
- Outperforms the 36x larger Qwen2-VL-72B-Instruct model on UAV tasks (72.13% vs 46.67% accuracy)
- Achieves 48.17% higher zero-shot accuracy than the base Qwen2-VL-2B-Instruct model
- Requires only 3.9 GB memory (FP16) or 2.5 GB (INT8) for inference, enabling edge deployment
Breakthrough Assessment
8/10
Demonstrates that a small (2B) model can radically outperform giant (72B) models in specialized domains via structured reinforcement learning, without needing human preference labels.