📝 Paper Summary
Text-to-Image Generation
Reinforcement Learning for Generative Models
Flow Matching
TempFlow-GRPO improves text-to-image alignment by introducing trajectory branching to assign precise rewards to specific timesteps and reweighting updates based on noise levels to prioritize high-impact early decisions.
Core Problem
Existing flow-based RL methods apply uniform optimization across all timesteps and rely on sparse terminal rewards, failing to account for the varying importance of decisions at different stages of generation.
Why it matters:
- Uniform optimization treats high-noise early steps (critical structure) the same as low-noise late steps (minor refinement), leading to inefficient exploration.
- Sparse terminal rewards make it difficult to determine which specific step in the generation trajectory improved or degraded the final image quality.
- Training separate Process Reward Models (PRMs) for intermediate steps is computationally expensive and difficult due to the semantic ambiguity of noisy states.
Concrete Example:
In standard Flow-GRPO, a policy update based on a final image reward assigns equal credit to the initial structural formation (step 0) and the final pixel refinement (step T). This dilutes the learning signal for critical early decisions that determine the image's overall composition.
Key Novelty
Temporally-Aware Group Relative Policy Optimization (TempFlow-GRPO)
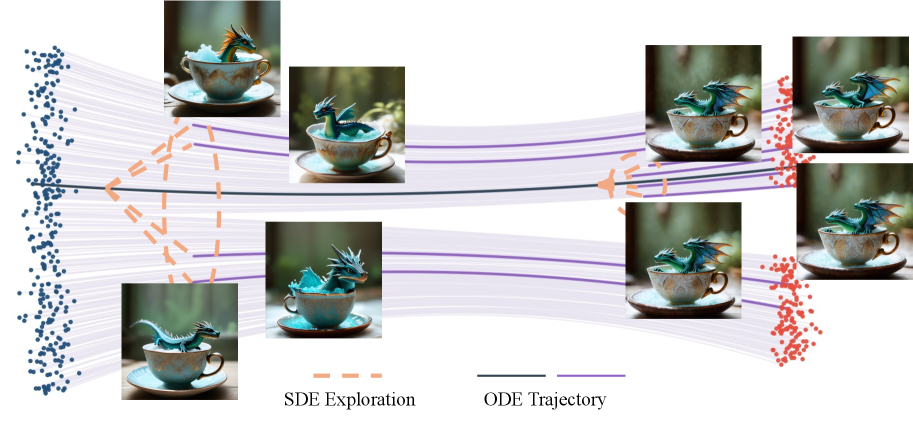
- Trajectory Branching: Isolates the effect of a single timestep by evolving deterministically until step k, injecting noise only at k, and then finishing deterministically; this attributes the final reward variance solely to the action at k.
- Noise-Aware Policy Weighting: Scales the optimization loss for each timestep proportional to its intrinsic noise level, applying stronger updates to early high-noise steps and gentler updates to late refinement steps.
- Seed Group Strategy: Groups training trajectories by their initial noise seed to ensure reward comparisons reflect the branching exploration rather than random initialization differences.
Architecture
The TempFlow-GRPO framework illustrating the Trajectory Branching mechanism and Seed Group Strategy.
Evaluation Highlights
- Achieves 0.97 Geneval score, outperforming Flow-GRPO (0.88) and the base model (0.63) on compositional image generation.
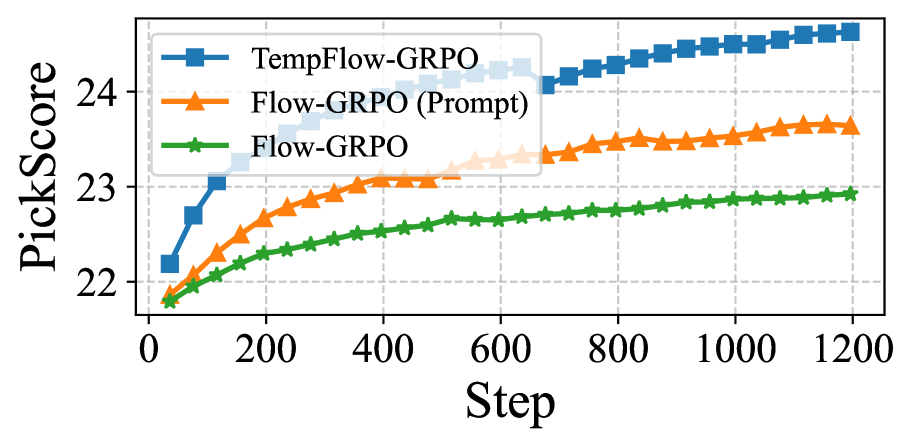
- Reaches 0.95 Geneval score in ~2,000 steps, whereas Flow-GRPO requires ~5,600 steps, demonstrating ~2.8x faster convergence.
- Surpasses Flow-GRPO by approximately 1.7% on the PickScore human preference alignment benchmark.
Breakthrough Assessment
8/10
Offers a mathematically grounded solution to the credit assignment problem in Flow Matching RL without requiring external process reward models. Significant gains in both convergence speed and final quality.