📊 Experiments & Results
Evaluation Setup
RLHF fine-tuning on multiple foundation models across image and video tasks.
Benchmarks:
- HPS-v2.1 Benchmark (Text-to-Image Generation)
- GenEval (Text-to-Image Generation)
- Pick-a-Pic (Text-to-Image Generation)
- VideoAlign (Text-to-Video and Image-to-Video Generation)
Metrics:
- HPS-v2.1 Score
- CLIP Score
- VideoAlign Score (Aesthetics, Motion)
- Pick-a-Pic Win Rate
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| DanceGRPO significantly improves aesthetic and alignment scores across Stable Diffusion and FLUX models. | ||||
| HPS-v2.1 Benchmark | HPS Score | 0.239 | 0.365 | +0.126 |
| HPS-v2.1 Benchmark | CLIP Score | 0.363 | 0.395 | +0.032 |
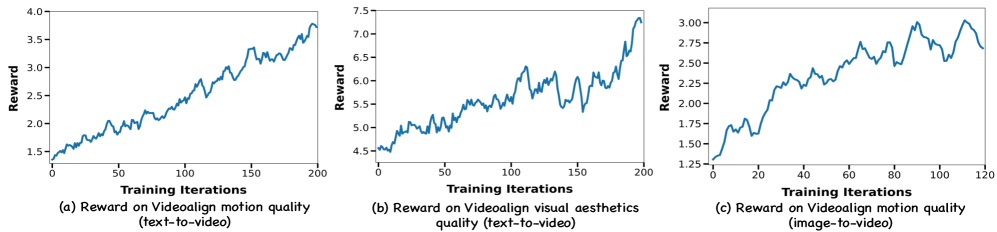
| Internal Evaluation | VideoAlign Motion Score | Not reported in the paper | Not reported in the paper | Not reported in the paper |
| Internal Evaluation | VideoAlign Motion Score | Not reported in the paper | Not reported in the paper | Not reported in the paper |
Experiment Figures
Impact of Best-of-N inference scaling on training convergence.
Main Takeaways
- Unified Framework: Successfully applies one algorithm (DanceGRPO) to Diffusion (SD1.4) and Rectified Flows (FLUX, Hunyuan), and across Image/Video tasks.
- Scalability: Unlike DDPO/DPOK which fail >100 prompts, DanceGRPO scales stably to >10,000 prompts.
- Video Capability: First RL method validated for video generation that solves VRAM issues of differentiable rewards.
- Binary Rewards: Demonstrated ability to learn from sparse, thresholded binary rewards (simulated DeepSeek-R1 style feedback).