📝 Paper Summary
Code Generation
Preference Optimization
Fine-grained Alignment
Focused-DPO improves code generation by identifying error-prone code segments via self-verification and upweighting them during preference optimization, rather than treating all code tokens equally.
Core Problem
Standard preference optimization (like DPO) treats all parts of a code sequence equally, failing to focus on the specific 'error-prone points' (often in the middle of complex logic) that actually determine correctness.
Why it matters:
- Small errors in critical code sections (e.g., a single incorrect operator) cause total program failure, unlike natural language where minor errors may be tolerable.
- Existing methods align overall style but overlook fine-grained critical logic, leading to code that looks correct (correct prefixes/suffixes) but fails on execution.
- Generating code from correct outputs at error-prone points can boost accuracy to ~90%, while incorrect choices there drop it to ~3%, showing the disproportionate impact of these segments.
Concrete Example:
In a Python function, the header and return statement (prefix/suffix) might be identical in both correct and incorrect versions. The error lies solely in a specific 'middle' logic block (e.g., a loop condition). Standard DPO averages the loss over the whole sequence, diluting the signal from this critical error point.
Key Novelty
Focused Direct Preference Optimization (Focused-DPO) & Error-Point Identification
- Uses a PageRank-based self-verification loop to identify which specific segments of generated code (the 'mid' parts) correlate most with passing/failing tests.
- Constructs a fine-grained preference dataset where 'chosen' and 'rejected' pairs share common prefixes/suffixes but differ at these error-prone points.
- Modifies the DPO loss function to explicitly upweight the reward difference for these critical 'mid' sections while downweighting the less informative suffixes.
Architecture
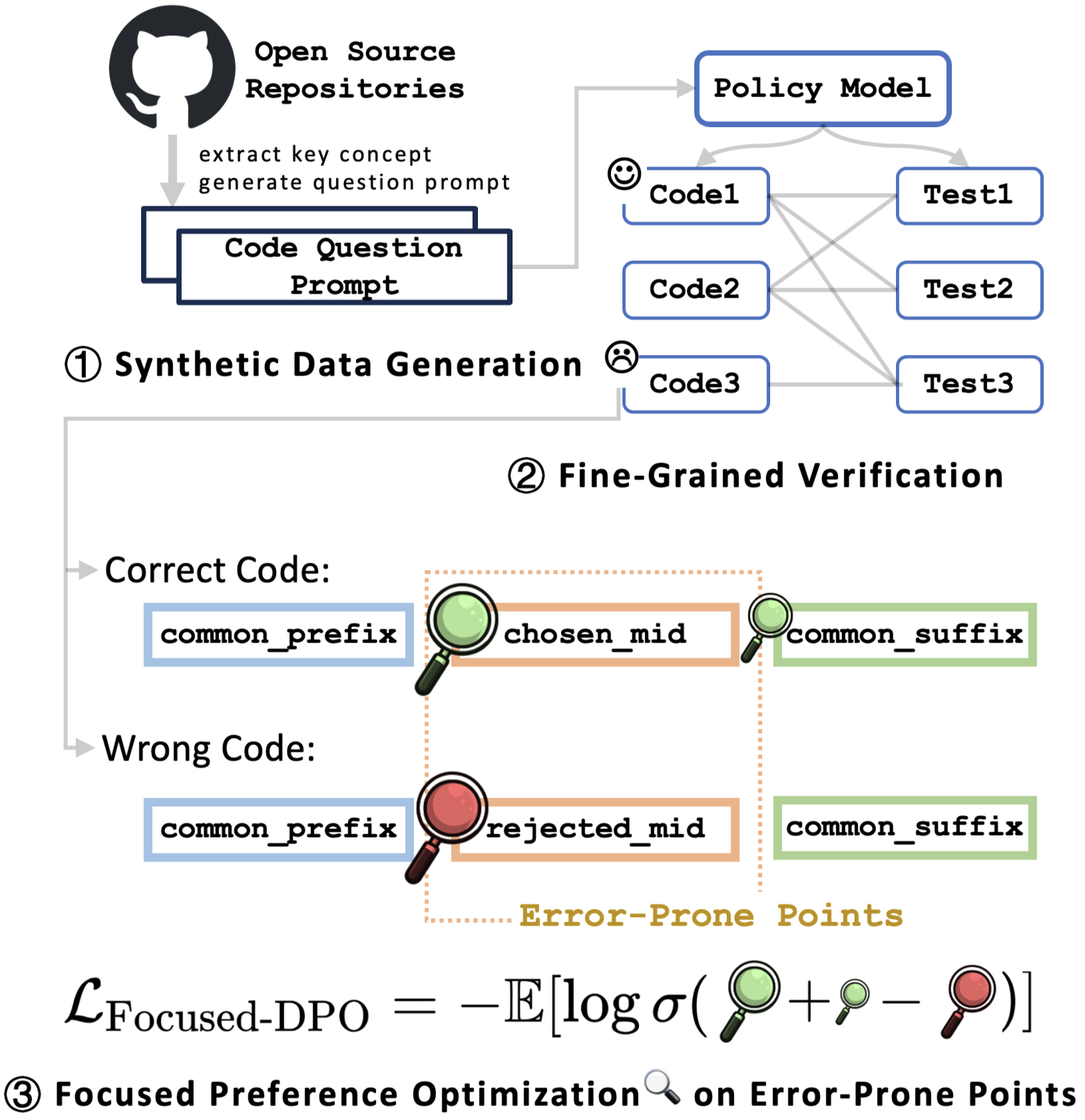
The Focused-DPO framework pipeline, illustrating the three main stages: Data Generation, Error-Point Identification, and Focused Preference Optimization.
Evaluation Highlights
- +42.86% relative improvement on LiveCodeBench (Hard) for Qwen2.5-Coder-7B compared to the base model, despite the model already undergoing large-scale alignment.
- Outperforms standard DPO by significant margins on HumanEval(+) and MBPP(+), demonstrating that focused optimization is more data-efficient than standard global preference learning.
- Verification accuracy (Pass@1) improves consistently across multiple base models (DeepSeek-Coder, CodeLlama, Qwen2.5) using the Focused-DPO framework.
Breakthrough Assessment
7/10
Strong conceptual contribution in identifying that code errors are localized and should be weighted differently. The method is intuitive and shows solid gains on hard benchmarks, though it relies on standard DPO mechanics.
