📝 Paper Summary
Offline Reinforcement Learning
Model-Based Reinforcement Learning (MBRL)
Robotics
RWM-U enables effective offline reinforcement learning on physical robots by augmenting autoregressive world models with ensemble-based uncertainty estimation to penalize unreliable predictions during long-horizon policy optimization.
Core Problem
Standard model-based offline RL fails on real robots because dynamics models hallucinate rewards in out-of-distribution states, and compounding errors in long-horizon rollouts lead to catastrophic policy failure.
Why it matters:
- Collecting real-world robot data is expensive and risky; offline RL allows reusing past logs (static datasets) without new interaction
- Current offline methods work in simulation but struggle with the noise, bias, and partial observability inherent in physical robotics
- Robustly handling distribution shift is essential for deploying policies trained on finite datasets to the real world
Concrete Example:
When a robot policy is optimized with a low uncertainty penalty, it exploits model inaccuracies ('hallucinations'), causing the physical robot (e.g., ANYmal D) to attempt unstable locomotion strategies that lead to falls or collisions, as the model falsely predicted these states would yield high rewards.
Key Novelty
Uncertainty-Aware Robotic World Model (RWM-U) with MOPO-PPO
- Extends autoregressive world models with a bootstrap ensemble of prediction heads to quantify epistemic uncertainty (uncertainty due to lack of data) over long horizons
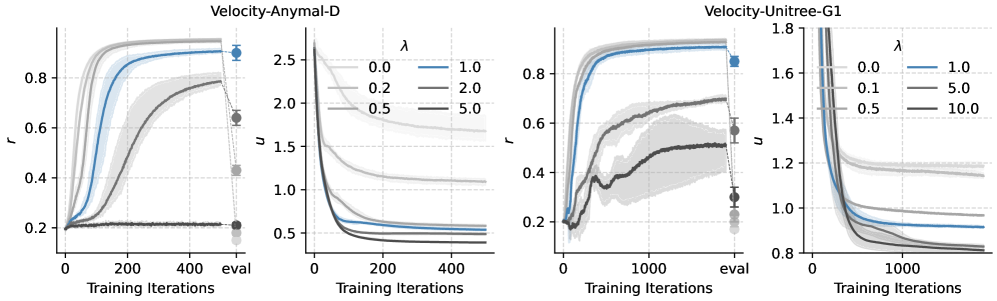
- Integrates this uncertainty into PPO (Proximal Policy Optimization) by subtracting an uncertainty penalty from the reward during imagined rollouts, forcing the policy to stay within trustworthy regions of the model
Architecture

System overview of the RWM-U pipeline, showing the autoregressive world model with ensemble heads and the integration into the MOPO-PPO policy optimization loop.
Evaluation Highlights
- Demonstrates the first known success of uncertainty-penalized offline MBRL (Model-Based RL) controlling full-scale tasks on physical robots (ANYmal D and Unitree G1)
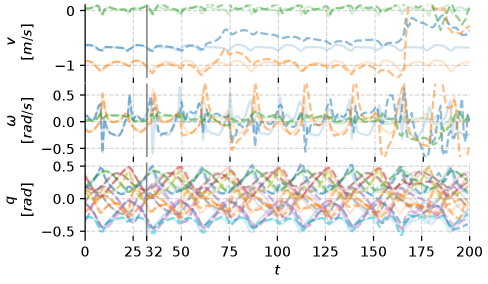
- Epistemic uncertainty estimates correlate strongly with actual model prediction errors over 32-step autoregressive rollouts, validating the uncertainty mechanism
- Policies trained on fused real-world and simulation data outperform online model-free baselines trained solely in simulation
Breakthrough Assessment
8/10
Significant step in making offline RL practical for robotics. Moving from simulation benchmarks to successful hardware deployment on quadrupeds and humanoids using offline data is a high bar.