📝 Paper Summary
Chinese Spelling Correction (CSC)
Zero-shot Learning
Reinforcement Learning for NLP
CEC-Zero enables LLMs to learn Chinese spelling correction without human labels by training on self-generated errors and rewarding corrections that achieve semantic consensus among multiple sampled outputs.
Core Problem
Existing Chinese spelling correction methods rely on costly human-annotated datasets or rigid supervised fine-tuning, making them brittle to novel error types and domain shifts.
Why it matters:
- Collecting high-quality, up-to-date error annotations is prohibitively expensive due to the non-uniqueness of valid corrections
- Standard supervised models memorize specific error patterns and fail to generalize to new domains or complex error types like character splitting
- Current LLMs still struggle with sentence-level accuracy on open-domain correction tasks despite general competence
Concrete Example:
A BERT-based model trained on fixed error patterns might fail to correct a novel homophone error or a split character (e.g., splitting one character into two valid but incorrect ones) because it hasn't seen that specific corruption pattern in its training data.
Key Novelty
Self-Supervised RL with Cluster-Consensus Rewards
- Synthesize error-filled sentences from clean text using a diverse perturbation library (homophones, splits, etc.) to create training inputs without manual labeling
- Compute a 'cluster-consensus' reward by sampling multiple corrections from the LLM and rewarding outputs that cluster together semantically and align with the original clean text
- Optimize the model using PPO (Proximal Policy Optimization) against this self-generated, label-free reward signal
Architecture
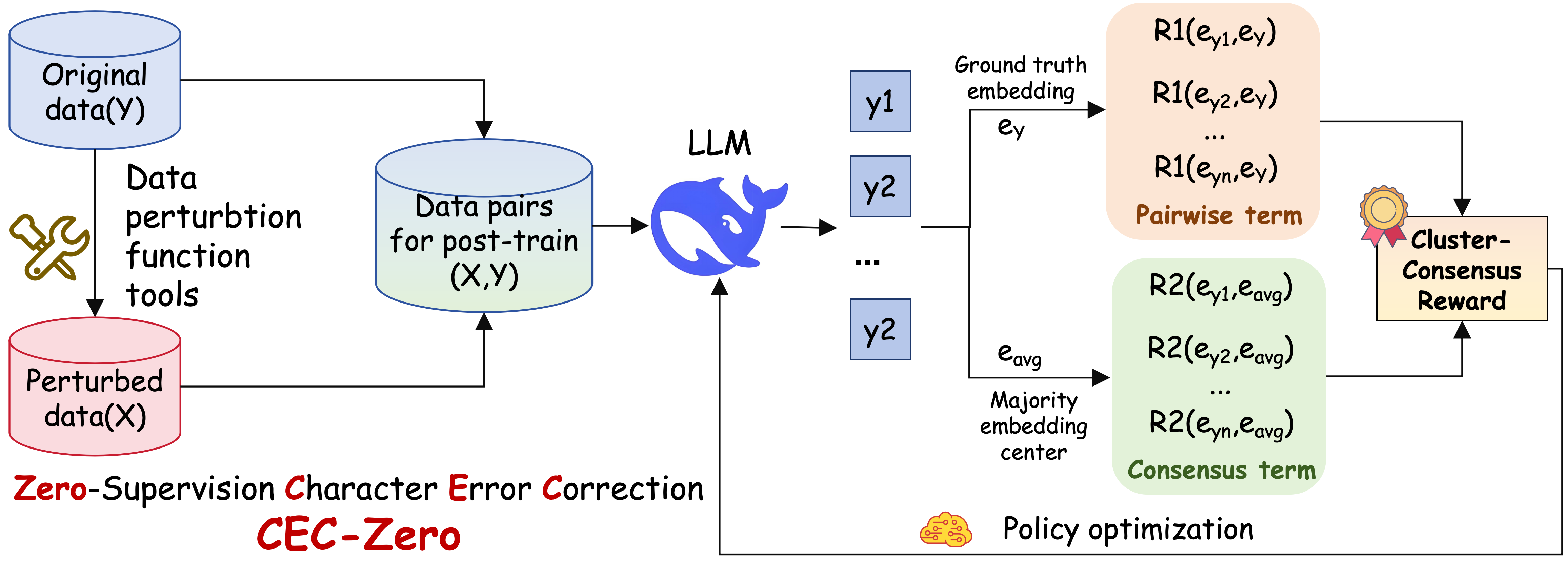
Overview of the CEC-Zero framework including data generation, policy rollout, and reward computation.
Evaluation Highlights
- +10–13 F1 points improvement over supervised BERT baselines on 9 public and industrial benchmarks
- +5–8 F1 points improvement over strong LLM fine-tuned baselines (like ReLM and C-LLM)
- Generalization gap bounded to <0.0003 (theoretically) with 44M synthetic pairs, ensuring robust performance on noisy real-world data
Breakthrough Assessment
9/10
Establishes a new paradigm for zero-supervision correction that significantly outperforms supervised methods. The theoretical backing for the reward signal and strong empirical gains make it a major advance.