📝 Paper Summary
Code Generation
Reinforcement Learning for Code
Program Synthesis
PPOCoder optimizes code generation models using PPO with a multi-component reward incorporating compiler feedback, AST matching, and Data Flow Graph alignment to ensure syntactic and functional correctness.
Core Problem
Pre-trained language models for code rely on supervised token-matching objectives, which often fail to ensure generated code is compilable or functionally correct.
Why it matters:
- Models like CodeBERT and CodeGPT frequently generate non-compilable code (high syntax error rates)
- Standard cross-entropy loss does not capture non-differentiable properties like passing unit tests or compiler checks
- Existing RL methods for code are often task-specific (e.g., only synthesis) or language-specific (e.g., only Python), lacking a generalizable framework
Concrete Example:
A model might generate code that looks correct token-by-token but misses a variable definition or bracket, causing compilation failure. Standard supervised learning penalizes this only slightly (per token), whereas a compiler rejects it entirely.
Key Novelty
PPOCoder (PPO for Code Generation)
- Combines Proximal Policy Optimization (PPO) with a specialized reward function that integrates discrete compiler feedback (pass/fail) with dense structural rewards
- Uses Abstract Syntax Tree (AST) matching and Data Flow Graph (DFG) alignment as reward signals to guide syntactic and semantic structure
- Replaces standard cross-entropy regularization with a KL-divergence penalty during RL fine-tuning to prevent catastrophic forgetting while reducing memorization
Architecture
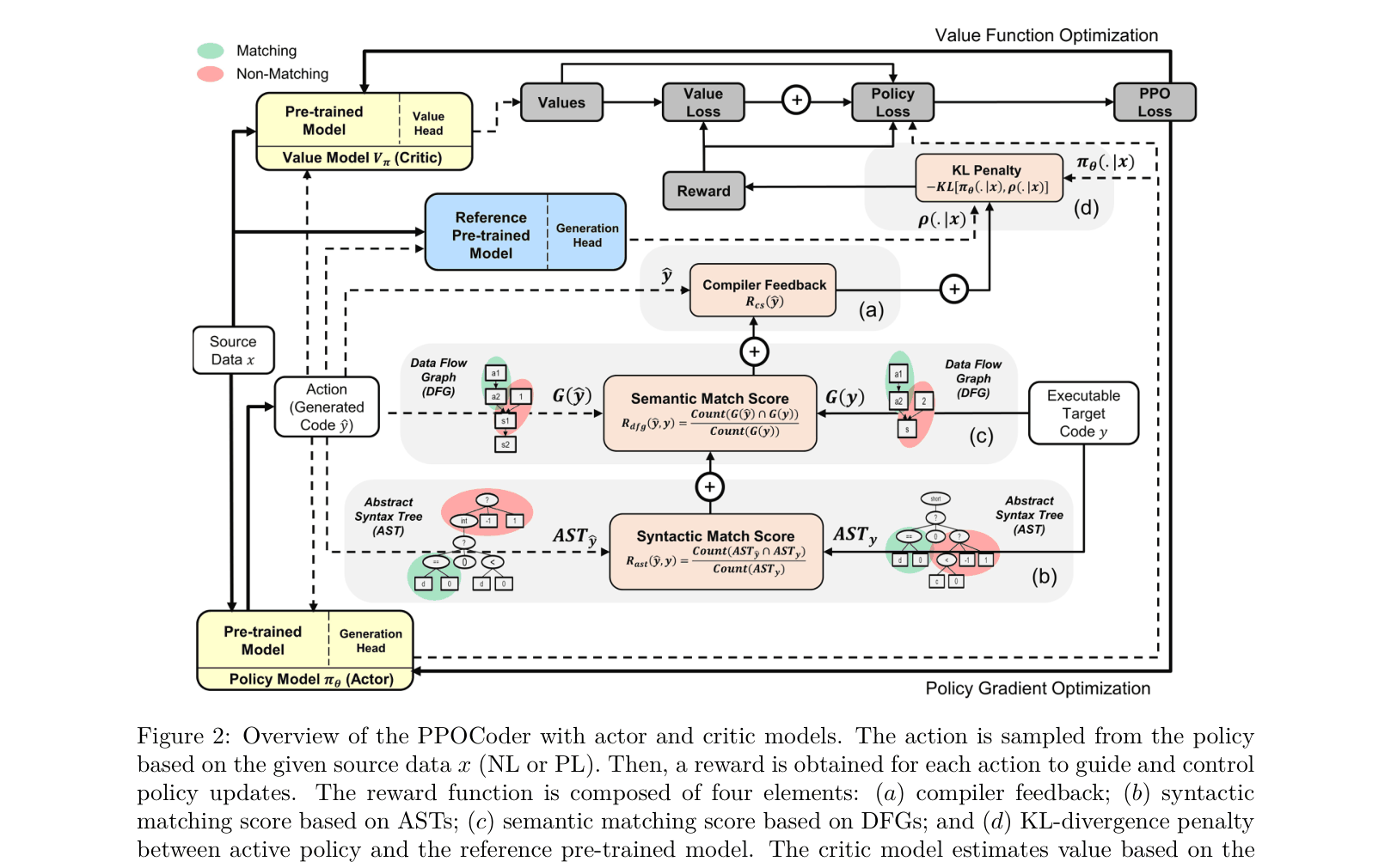
The RL training loop of PPOCoder. It details the Actor-Critic setup where the Policy (Actor) generates code, receives a multi-component reward (Compiler, AST, DFG, KL), and updates via PPO.
Evaluation Highlights
- Increases Code Completion compilation rate from 52.14% (CodeT5) to 97.68% on CodeSearchNet Python
- Achieves 82.80% compilation rate on Java Code Translation (XLCoST), improving over CodeT5 baseline (59.81%) by +22.99%
- Outperforms CodeRL on MBPP zero-shot program synthesis (68.2% vs 63.0% pass@80), showing better generalization
Breakthrough Assessment
8/10
Significant improvement in compilability across multiple languages and tasks. Successfully integrates multiple structural signals into RL, addressing the key weakness of LLMs in code generation.