📝 Paper Summary
Multi-step Reasoning
Reward Modeling
Inference-time Search
HGS-PRM improves multi-step reasoning accuracy by using a process-supervised reward model to guide a heuristic greedy search during inference, validating intermediate steps before proceeding.
Core Problem
Large Language Models suffer from cascading errors in multi-step reasoning tasks, where a single incorrect step invalidates the entire subsequent reasoning chain.
Why it matters:
- Current reasoning approaches like Chain of Thought (CoT) lack mechanisms to correct errors mid-generation, leading to error propagation
- Existing search methods like BFS/DFS or self-reflection can be computationally prohibitive or get stuck in repetitive loops due to context window limits
Concrete Example:
In a math problem requiring complex number calculation |(1-i)^8|, a standard model might make a calculation error in step 2 (e.g., calculating (1-i)^2 incorrectly). Without feedback, the model builds on this wrong intermediate value, inevitably leading to a wrong final answer (e.g., 32 instead of 16).
Key Novelty
Heuristic Greedy Search with Process-Supervised Reward Model (HGS-PRM)
- Deploys a step-level reward model (PRM) as a navigator during *inference* (decoding) rather than just for training (RLHF), evaluating every generated step
- Uses a greedy search algorithm that backtracks when the PRM detects a negative step, constraining the search space compared to exhaustive methods like BFS
- Introduces an automated pipeline to generate step-level reward data for code using Abstract Syntax Tree (AST) mutation and unit testing
Architecture
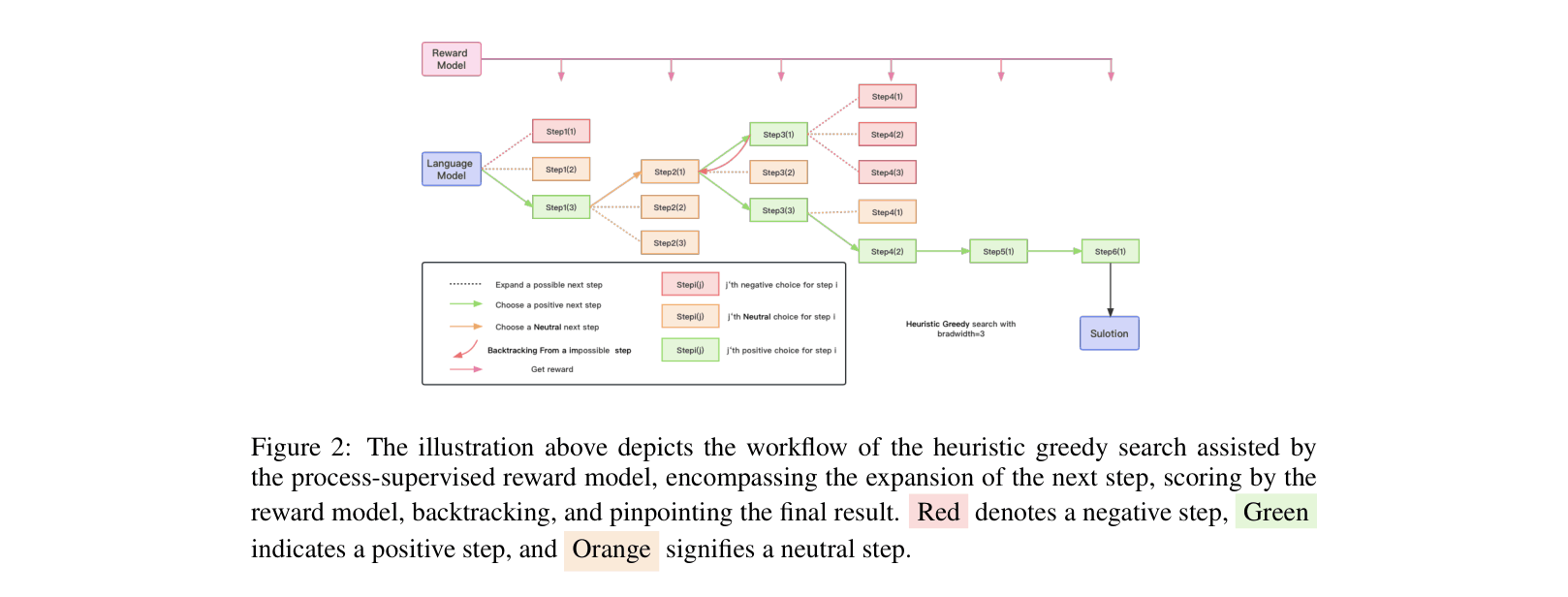
The workflow of the Heuristic Greedy Search assisted by the Process-Supervised Reward Model (HGS-PRM)
Evaluation Highlights
- +4.9% improvement in pass@1 on HumanEval using Code-LLaMA-Python-7B compared to Chain of Thought (CoT)
- +3.3% accuracy improvement on MATH benchmark using WizardMath-13B compared to CoT
- +2.2% accuracy improvement on GSM8K benchmark using WizardMath-13B compared to CoT
Breakthrough Assessment
7/10
Solid application of PRMs to inference-time search with demonstrable gains. The automated generation of code PRM data via mutation testing is a clever, scalable contribution.