📝 Paper Summary
UAV Navigation
Safe Reinforcement Learning
Sim-to-Real Transfer
NavRL combines deep reinforcement learning with a velocity obstacle-based safety shield to enable quadcopters to navigate cluttered dynamic environments safely without retraining in the real world.
Core Problem
Traditional UAV navigation relies on complex, handcrafted modules that struggle in changing environments, while standard RL methods suffer from the sim-to-real gap and lack safety guarantees against severe failures.
Why it matters:
- Autonomous UAVs in search and rescue or inspection tasks must avoid moving obstacles (e.g., humans, other drones) in real-time.
- End-to-end learning methods often fail in the real world due to sensory noise and discrepancies between simulation and reality.
- Neural network policies are 'black boxes' that cannot theoretically guarantee safety, necessitating a mechanism to prevent dangerous actions during deployment.
Concrete Example:
A UAV trained only in simulation might collide with a moving person because it misinterprets noisy depth camera data or because the RL policy, encountering an unfamiliar state, outputs a velocity command that intersects the person's future path.
Key Novelty
NavRL (Navigation with RL + Safety Shield)
- Separates static and dynamic obstacle representations: static obstacles use ray-casting on a voxel map, while dynamic obstacles use estimated states (position/velocity) to bridge the sim-to-real gap.
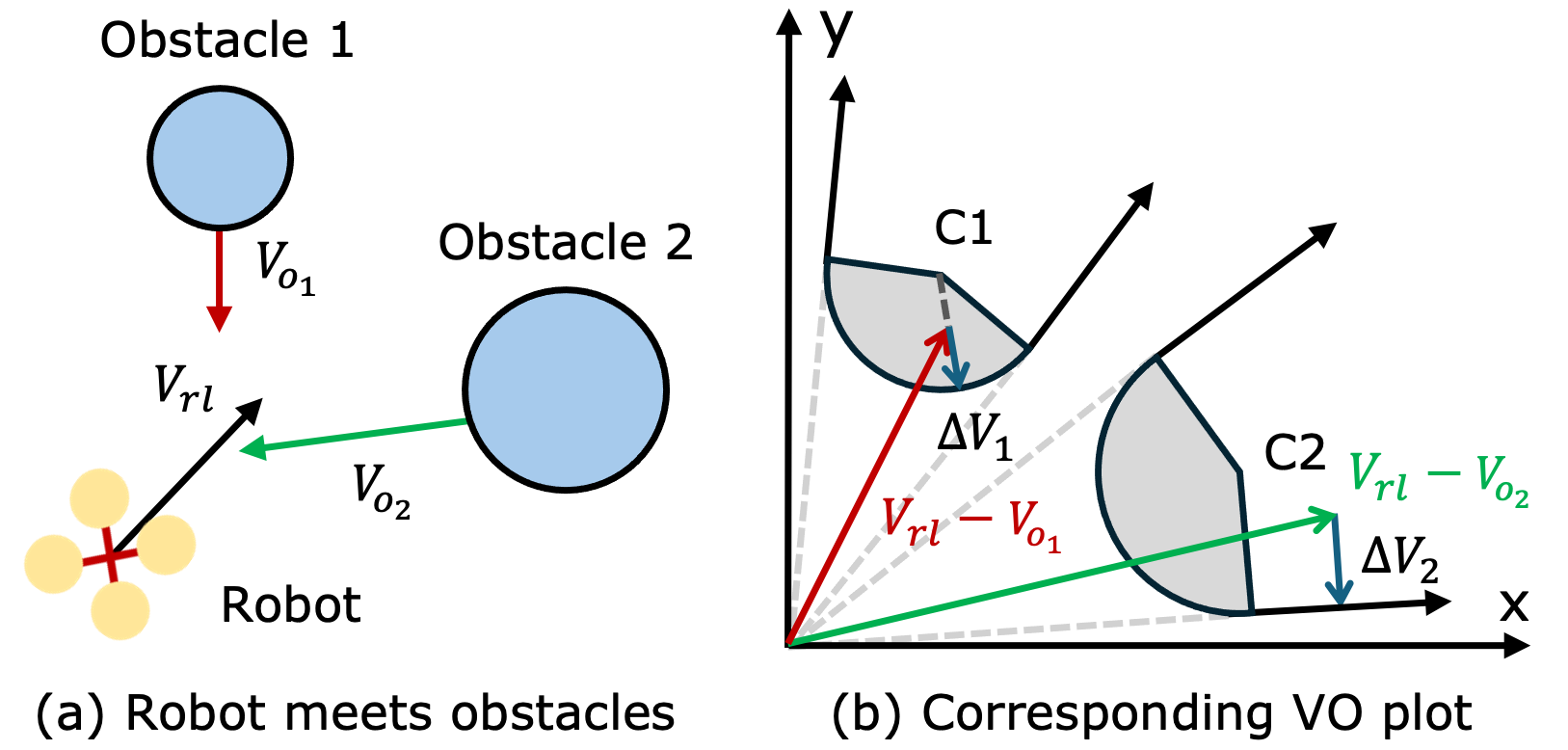
- Applies a post-hoc safety shield using Linear Programming based on Velocity Obstacles (VO) to project unsafe RL actions into a safe region during execution.
- Uses a parallel training pipeline in NVIDIA Isaac Sim to train thousands of drones simultaneously, accelerating convergence.
Architecture
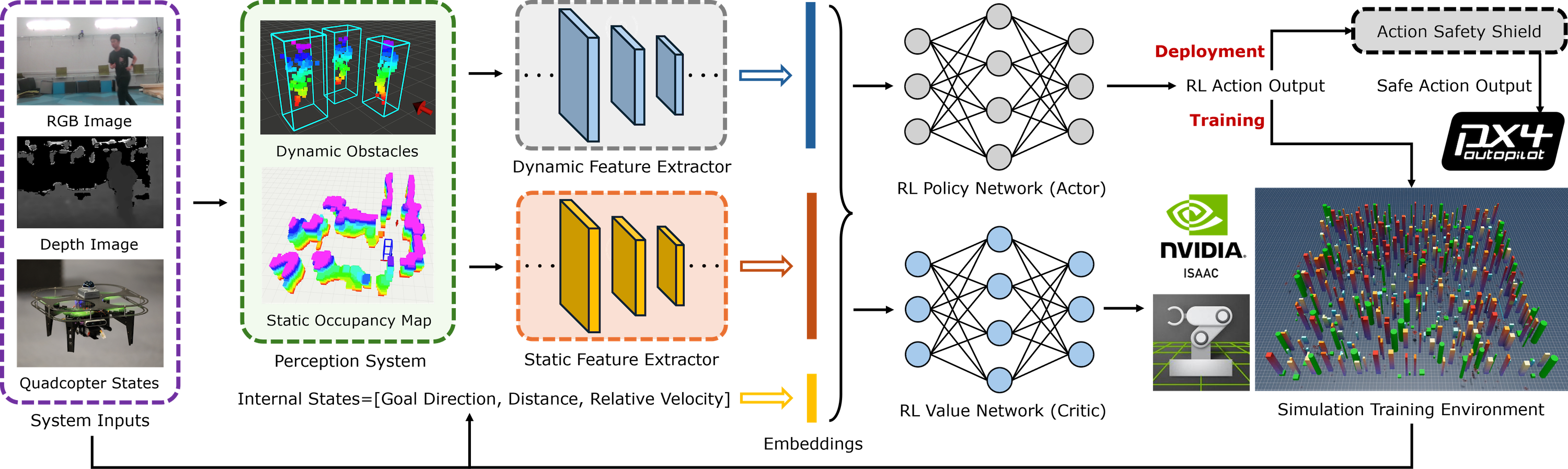
The complete NavRL framework pipeline from perception to control.
Evaluation Highlights
- Achieved highest success rate (82.5%) and lowest collision rate (7.0%) in dynamic forest environments compared to baselines like VO and standard RL.
- Zero-shot transfer demonstrated in real-world experiments, successfully avoiding pedestrians and static obstacles without fine-tuning.
- Safety shield intervention reduced collision rates significantly compared to raw policy outputs in highly cluttered dynamic scenarios.
Breakthrough Assessment
7/10
Strong practical contribution combining RL with control-theoretic safety shields for robust sim-to-real transfer. While component techniques (PPO, VO) are known, the integrated framework and successful zero-shot physical deployment are significant.