📊 Experiments & Results
Evaluation Setup
Mathematical reasoning tasks with binary success/failure feedback
Benchmarks:
- MATH (Competition-level mathematics)
- GSM8K (Grade school math)
- ORZ57K (Large amalgamated math dataset)
Metrics:
- Test Accuracy (Pass@1)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| PPO experiments showing LILO improves both speed and final accuracy on MATH and GSM8K. | ||||
| MATH | Test Accuracy | 19.1 | 21.8 | +2.7 |
| GSM8K | Test Accuracy | 51.1 | 53.2 | +2.1 |
| VinePPO experiments demonstrating effectiveness on a more advanced RL algorithm. | ||||
| MATH | Test Accuracy | 22.8 | 24.9 | +2.1 |
| GSM8K | Test Accuracy | 53.2 | 55.9 | +2.7 |
| GRPO experiments on a larger dataset and model. | ||||
| ORZ57K | Test Accuracy | 35.5 | 37.1 | +1.6 |
Experiment Figures
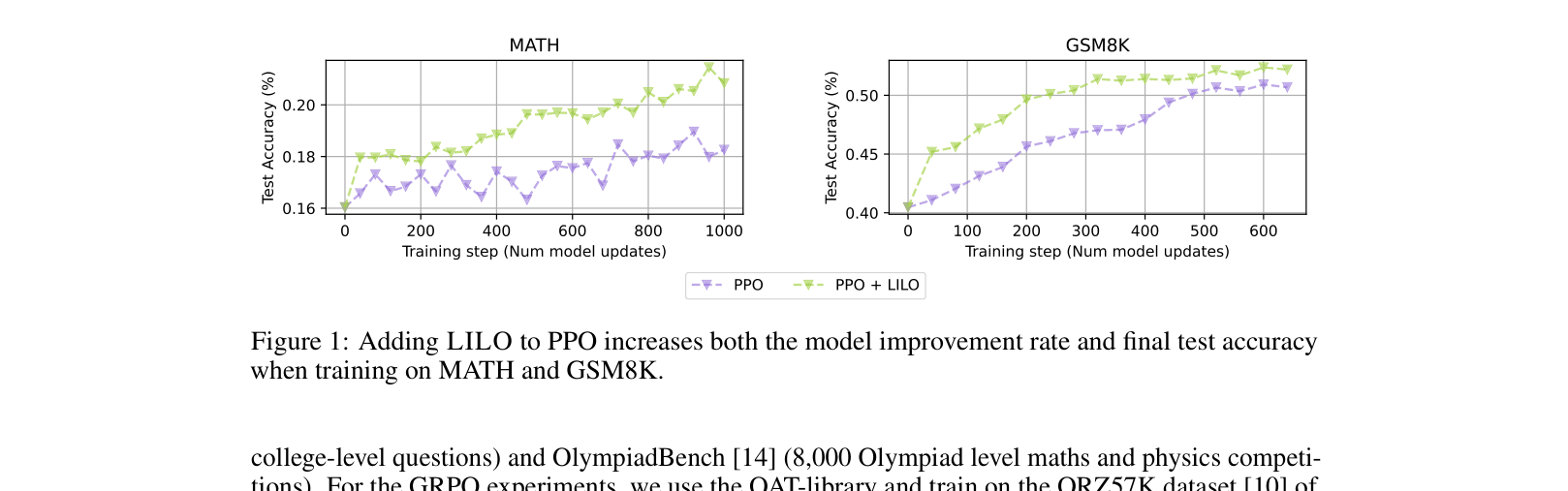
Test accuracy curves for PPO vs PPO+LILO on MATH and GSM8K over training steps.
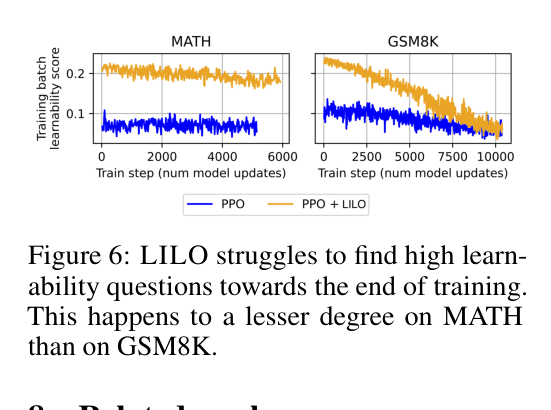
The average learnability of questions in the training batch over time.
Main Takeaways
- Prioritizing learnability consistently improves final test accuracy across different RL algorithms (PPO, VinePPO, GRPO) and datasets.
- LILO significantly reduces training time (up to 3.3x fewer steps) by avoiding non-informative gradients from too-easy or too-hard questions.
- The difficulty of finding learnable questions increases as training progresses, requiring larger candidate pools (rejection sampling) in later stages.
- Questions selected by LILO naturally correlate with higher reasoning complexity (more steps) over time, creating an implicit curriculum.