📝 Paper Summary
LLM Reasoning
Reinforcement Learning (RL)
Preference Optimization
TRPA improves LLM reasoning by converting rule-based evaluations into preference pairs and optimizing them via a trust-region constrained objective that guarantees monotonic improvement toward a target distribution.
Core Problem
Reward-based RL (like PPO) suffers from complexity and reward hacking, while current online preference-based methods (like Online DPO) lack theoretical guarantees for reasoning tasks, often leading to instability and inferior performance compared to rule-based baselines.
Why it matters:
- Reasoning tasks require precise, stable optimization where standard alignment methods often fail to converge or generalize
- Existing online DPO methods exhibit theoretical bias (not optimizing the true target distribution), preventing them from matching the performance of methods like GRPO
- Designing explicit reward functions is difficult and prone to 'hacking', where models maximize the score without solving the problem
Concrete Example:
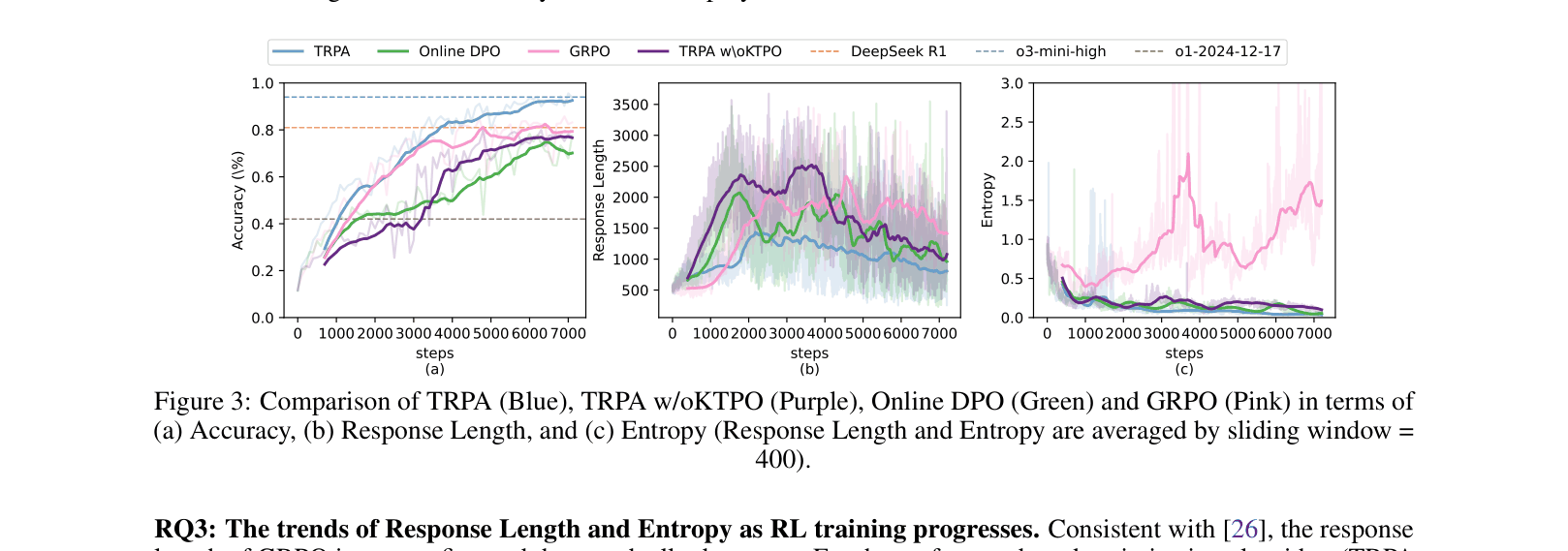
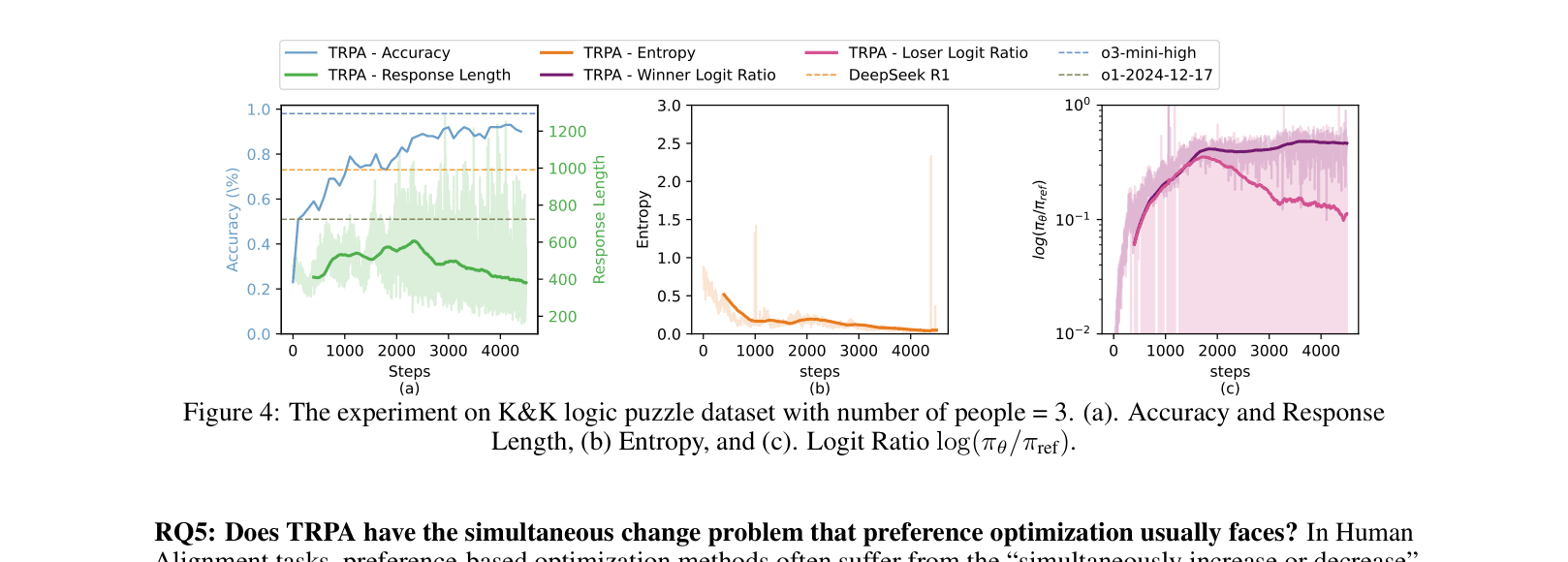
In logic puzzles, standard Online DPO often causes the 'simultaneous change' problem where the probabilities of both correct (winner) and incorrect (loser) responses increase together. TRPA's update rule ensures the winner's logit ratio increases while the loser's decreases, as shown in the paper's analysis of logit trajectories.
Key Novelty
Trust Region Preference Approximation (TRPA)
- Converts rule-based checks (format, accuracy) into discrete preference levels (Level 1 to 4) to construct training pairs dynamically during online rollouts
- Introduces a KL-regularized preference loss that approximates the 'Posterior Boltzmann' target distribution, providing a theoretical monotonic improvement guarantee lacking in Online DPO
- Applies 'Kahneman-Tversky Preference Optimization' (KTPO), using anisotropic hyperparameters to weigh high-quality responses differently, inspired by human sensitivity to gains/losses
Architecture
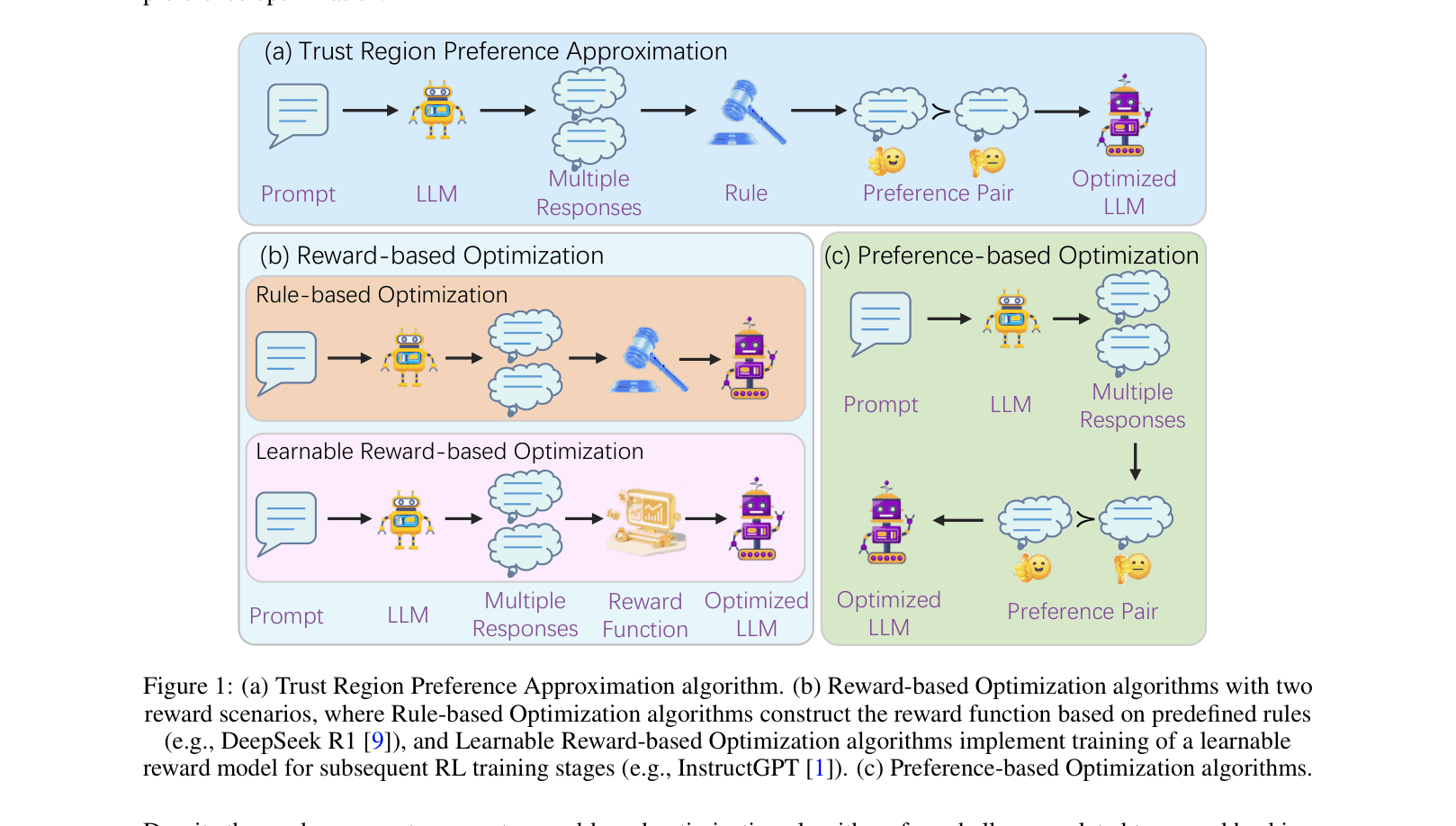
Comparison of RL pipelines: (a) TRPA, (b) Reward-based Optimization (like PPO/GRPO), and (c) Preference-based Optimization.
Evaluation Highlights
- Achieves 93.8% average accuracy on K&K logic puzzles, matching o3-mini-high (93.5%) and significantly outperforming DeepSeek-R1 (80.7%)
- Improves mathematical reasoning on AIME 2024 to 57%, a +14 point absolute gain over the base DeepSeek-R1-Distill-Qwen-7B model (43%)
- Demonstrates strong Out-Of-Distribution (OOD) generalization, scoring 86% on 8-person logic puzzles (unseen during training) compared to DeepSeek-R1's 83% and GPT-4o's 11%
Breakthrough Assessment
8/10
Offers a theoretically grounded fix to Online DPO's instability and matches or beats specialized reasoning baselines (GRPO, DeepSeek-R1) with a simpler, reward-free preference framework.