📝 Paper Summary
Autonomous Drone Racing
Vision-Based Control
Model-Based Reinforcement Learning
Dream to Fly utilizes DreamerV3 to learn agile drone racing policies directly from raw camera pixels to control commands without explicit state estimation or intermediate representations.
Core Problem
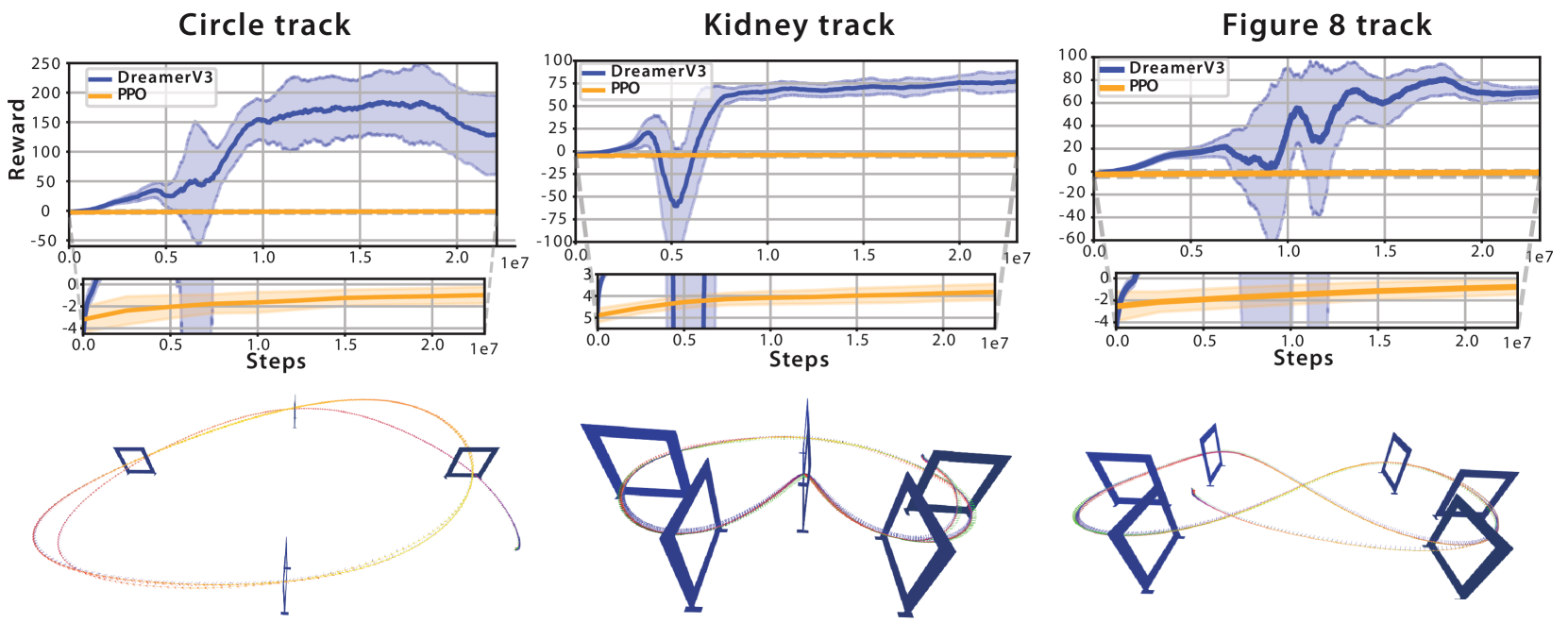
Existing vision-based drone racing methods rely on simplified intermediate representations (like gate masks) or extensive imitation learning because model-free RL is too sample-inefficient to learn directly from high-dimensional raw pixels.
Why it matters:
- Discarding background information via intermediate representations limits navigation capabilities when gates aren't visible
- Bridging the gap to human-level piloting requires processing raw visual cues (texture, horizon) directly
- Model-free RL methods like PPO struggle to converge on high-dimensional pixel inputs in reasonable timeframes
Concrete Example:
Previous state-of-the-art methods preprocess the camera feed into a binary mask showing only gates. If the drone faces a wall with no gate in view, the binary mask is blank, discarding texture cues like the floor or horizon that a human (or this method) could use for stabilization.
Key Novelty
End-to-End Model-Based RL for Agile Flight
- Learns a world model (transition dynamics) in a compact latent space directly from raw RGB images, allowing the agent to imagine future trajectories
- Trains the control policy entirely within this learned imagination rather than requiring millions of real-world interactions
- Eliminates the need for 'perception-aware' reward shaping; the agent naturally learns to look at gates to minimize uncertainty in its world model
Architecture
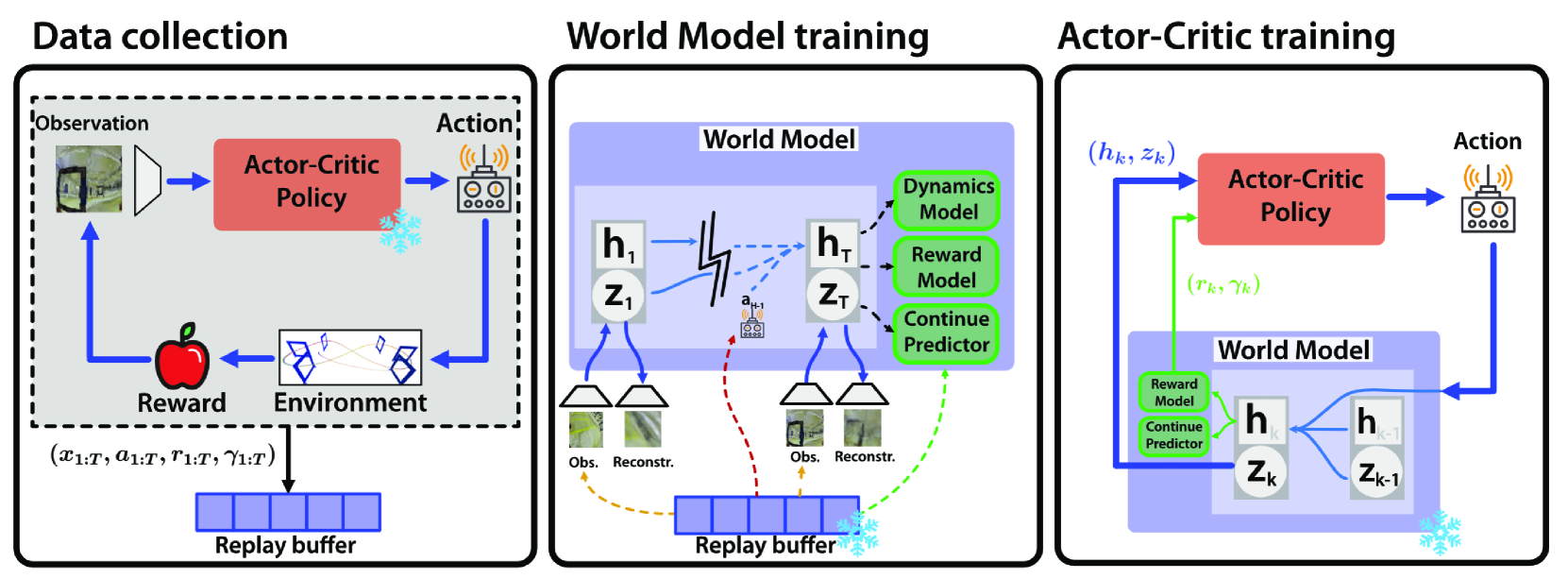
The training loop of the DreamerV3 agent involving World Model learning and Actor-Critic learning.
Evaluation Highlights
- First autonomous agent to fly a quadrotor using unique pixel-to-command mapping without intermediate representations or state estimation
- Achieves 100% success rate in simulation gate traversal, whereas the PPO baseline fails completely (0% success)
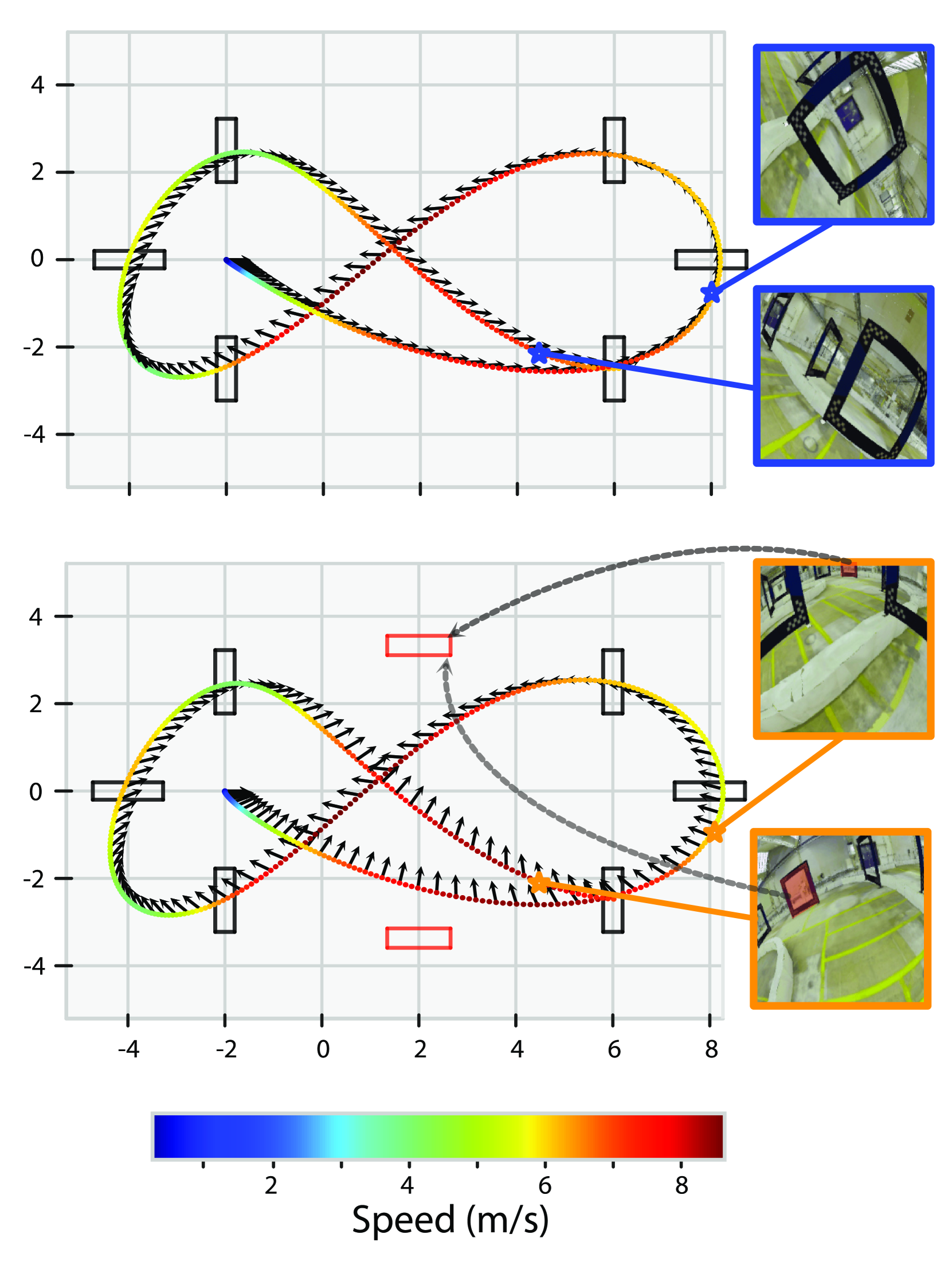
- Successfully deploys zero-shot to the real world (with domain randomization) achieving agile flight up to 1.5 m/s
Breakthrough Assessment
9/10
Achieves a long-standing goal in robotics: agile flight from raw pixels without explicit state estimation. The total failure of strong baselines (PPO) highlights the difficulty of the task and the significance of the solution.