📝 Paper Summary
Reinforcement Learning for LLMs
Mathematical Reasoning
Policy Optimization Algorithms
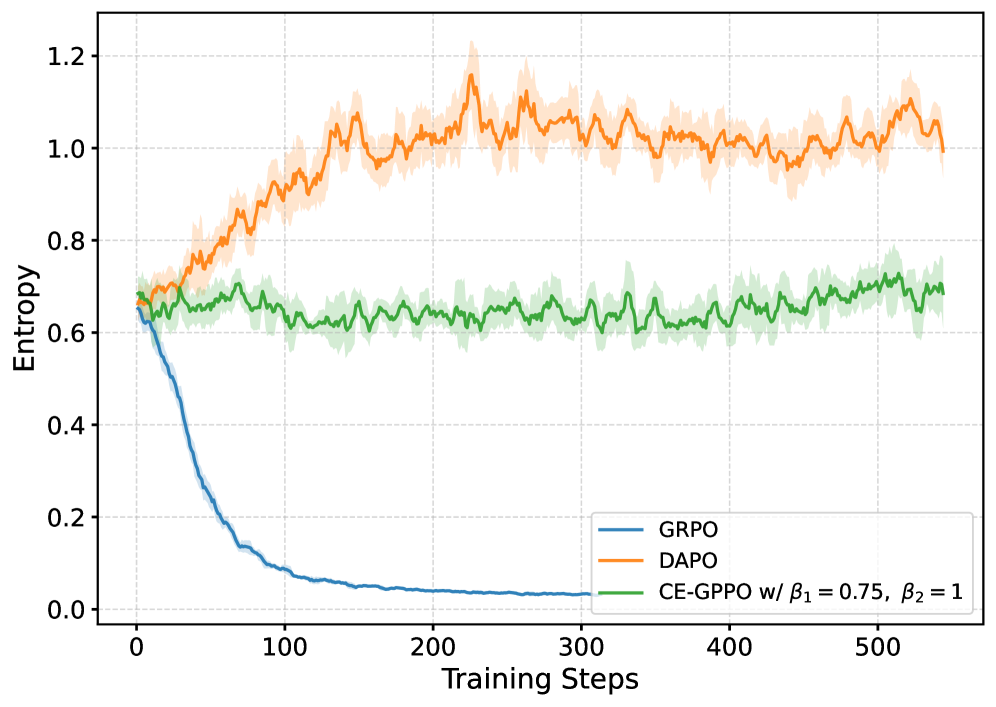
CE-GPPO stabilizes reinforcement learning by reintroducing gradients from clipped low-probability tokens using a stop-gradient mechanism to explicitly regulate policy entropy.
Core Problem
Standard PPO clipping discards gradients from low-probability tokens, causing either entropy collapse (premature convergence) or entropy explosion (instability) during RL training.
Why it matters:
- Entropy collapse prevents models from exploring diverse reasoning paths, leading to suboptimal solutions in complex tasks like math reasoning
- Existing fixes like 'clip-higher' (DAPO) only address one side of the problem, leading to potential over-exploration or instability
- Unregulated entropy dynamics make RL fine-tuning of Large Language Models notoriously unstable and sensitive to hyperparameters
Concrete Example:
In PPO, if a token's probability drops significantly (negative advantage, low probability), its ratio falls below 1-epsilon and its gradient is zeroed out. The model loses the signal to 'stop exploring this bad path', causing it to paradoxically explore even more, leading to entropy explosion.
Key Novelty
Gradient-Preserving Clipping Policy Optimization (CE-GPPO)
- Identifies that clipped tokens are usually low-probability tokens that are critical for regulating entropy: PA&LP (Positive Advantage & Low Prob) aid exploration, while NA&LP (Negative Advantage & Low Prob) aid exploitation
- Reintroduces these clipped gradients back into the update using a stop-gradient operator to keep their magnitude bounded but non-zero
- Uses two scaling coefficients to independently weight exploration-inducing gradients and exploitation-inducing gradients, balancing the entropy curve
Architecture
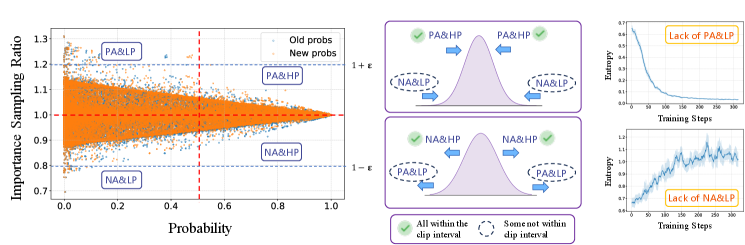
A conceptual illustration of the PPO clipping mechanism and how CE-GPPO modifies it. It shows the distribution of tokens relative to their probability and the clipping interval.
Evaluation Highlights
- Outperforms PPO and DAPO baselines on AIME24, AIME25, and MATH500 benchmarks across 1.5B and 7B model scales
- Achieves +3.0% accuracy improvement on AIME24 with the 7B model compared to the best baseline (DAPO)
- Maintains stable entropy throughout training, avoiding the rapid collapse seen in GRPO and the initial explosion seen in DAPO
Breakthrough Assessment
7/10
Offers a theoretically grounded and empirically effective fix for a fundamental PPO issue (entropy instability) in the context of LLM reasoning, with consistent gains.