📊 Experiments & Results
Evaluation Setup
Mathematical reasoning tasks requiring multi-step Chain-of-Thought (CoT) generation
Benchmarks:
- GSM8K (Grade school math word problems)
- MATH (Challenging mathematics problems)
Metrics:
- Accuracy (Pass@1)
- KL Divergence
- Value Estimation Error (MSE)
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| VinePPO consistently outperforms baselines on mathematical reasoning benchmarks. | ||||
| GSM8K | Accuracy | 64.81 | 66.86 | +2.05 |
| MATH | Accuracy | 35.10 | 38.32 | +3.22 |
| GSM8K | Accuracy | 64.67 | 66.86 | +2.19 |
| MATH | Wall-clock Time (normalized) | 3.0 | 1.0 | -2.0 |
Experiment Figures
A motivating example of a math problem where only one step is critical, but PPO's value network fails to identify it.
Training curves (Test Accuracy vs. Wall-clock Time) for GSM8K and MATH.
Main Takeaways
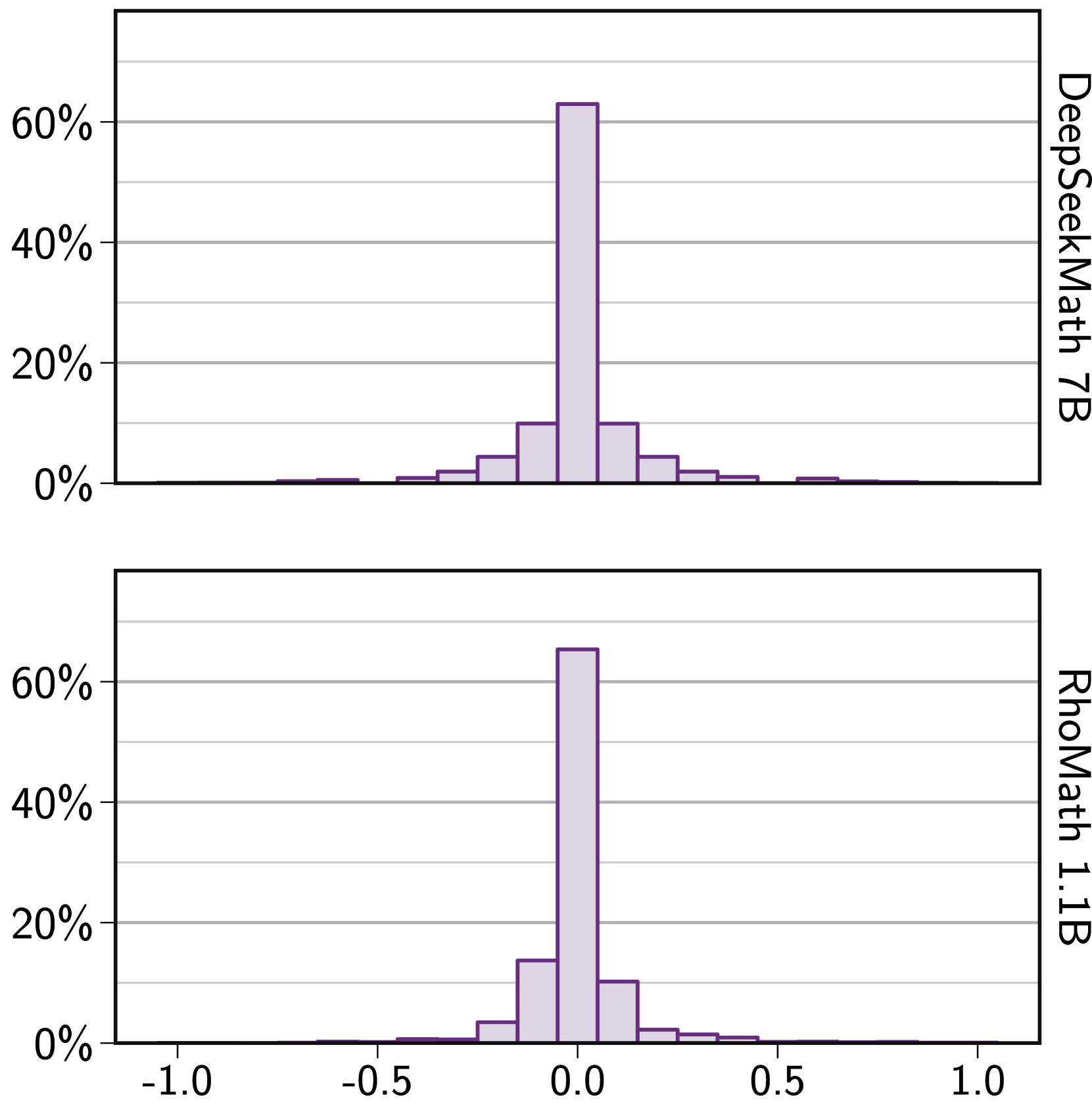
- Standard value networks in PPO produce high-variance, biased estimates for reasoning tasks, often failing to rank states better than random chance.
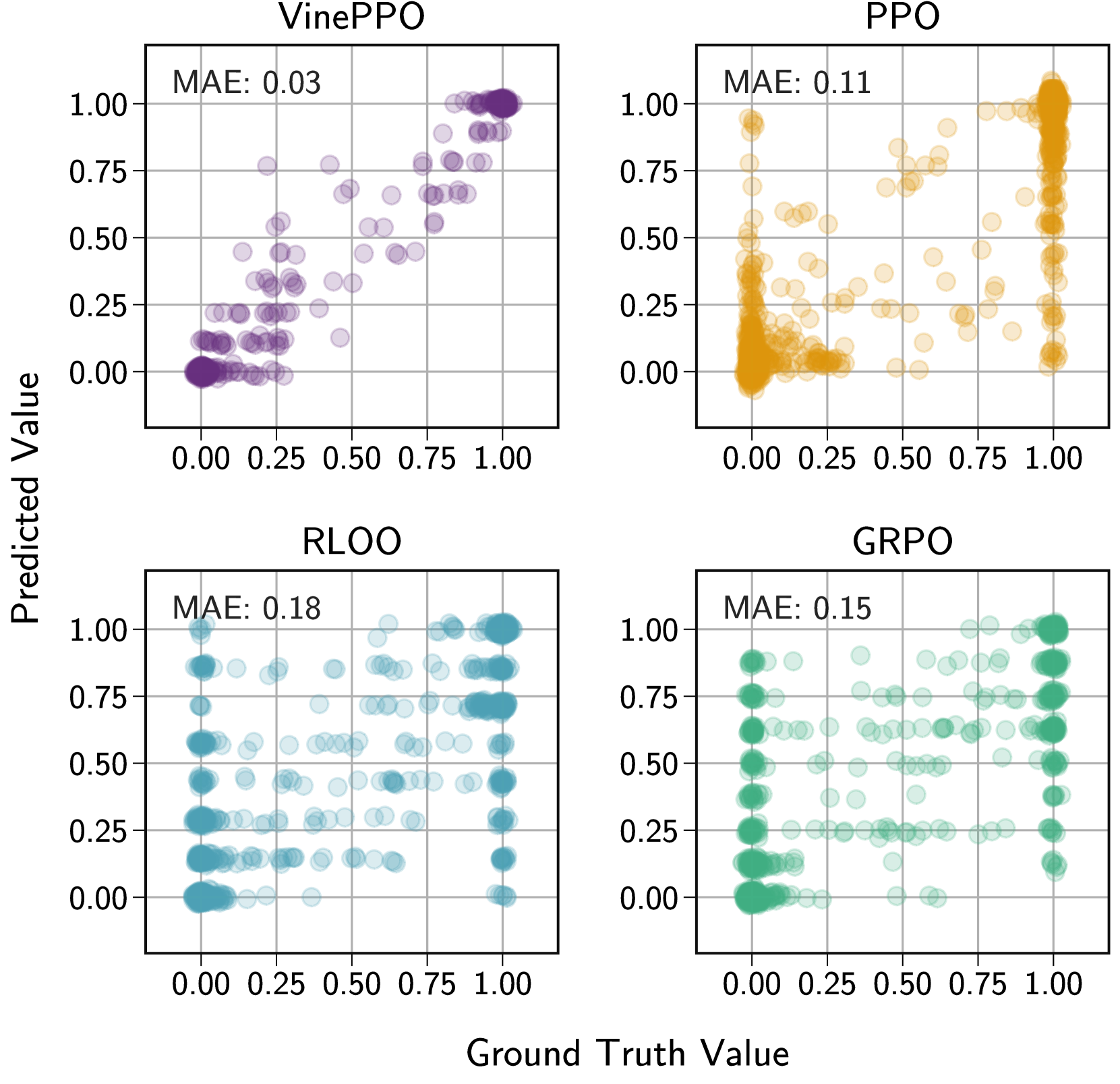
- VinePPO's Monte Carlo estimation provides accurate credit assignment, leading to better sample efficiency and generalization (higher test acc at same train acc).
- While MC rollouts add per-iteration computational cost, the improved signal quality allows the model to converge significantly faster in total wall-clock time.
- Dense, accurate credit assignment (VinePPO) outperforms sparse credit assignment methods (GRPO, RLOO) on complex reasoning tasks.