📝 Paper Summary
LLM Post-training
Reinforcement Learning (RL)
Entropy Regularization
AEnt adapts entropy regularization for LLMs by calculating entropy only on top-k tokens and dynamically adjusting the coefficient, preventing the failures of standard entropy methods in large vocabulary spaces.
Core Problem
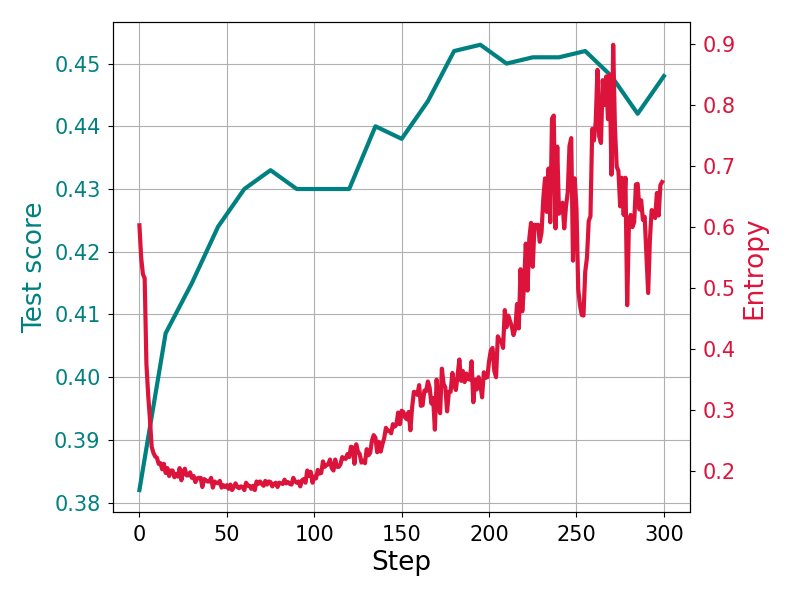
Standard entropy regularization, widely used in classic RL, fails in LLM training because the vocabulary space is massive and optimal tokens are sparse.
Why it matters:
- Without entropy control, policy gradient methods like PPO/GRPO suffer from collapse, where the model over-reinforces locally optimal actions and stops exploring.
- Existing entropy bonuses introduce massive bias in LLMs because pushing probability mass to hundreds of thousands of irrelevant tokens drowns out the signal for the few correct ones.
- Current LLM-RL methods often abandon entropy regularization entirely due to these failures, missing out on potential exploration and stability gains.
Concrete Example:
In a math reasoning task, an LLM might get stuck repeating a specific format that yields partial reward but incorrect answers. Standard entropy regularization would try to force the model to explore all 100,000+ tokens equally, effectively destroying the coherent generation needed to solve the problem, rather than just exploring plausible alternative reasoning steps.
Key Novelty
Adaptive Clamped Entropy (AEnt)
- Calculates entropy using a re-normalized policy over a small, dynamic set of 'top-k' tokens rather than the full vocabulary, focusing exploration on plausible next tokens.
- Automatically adjusts the entropy coefficient during training to keep the clamped entropy within a target range, increasing regularization when the policy collapses and decreasing it when exploration is sufficient.
Architecture
The pseudocode for the AEnt algorithm, detailing the loop of data sampling, advantage estimation, and the specific update steps for the policy and entropy coefficient.
Evaluation Highlights
- +3.4% accuracy on MATH dataset using Qwen2.5-Math-1.5B compared to the GRPO baseline.
- +5.4% accuracy on MATH dataset using DeepSeek-R1-Distill-Qwen-1.5B compared to the GRPO baseline.
- Outperforms static entropy regularization and recent methods like constant-coefficient entropy consistently across multiple benchmarks.
Breakthrough Assessment
7/10
Offers a theoretically grounded and empirically effective fix for a known failure mode in LLM-RL (entropy regularization). While a modification to existing algorithms rather than a new paradigm, it significantly improves standard baselines.