📝 Paper Summary
LLM Reasoning
Reinforcement Learning (RL) for LLMs
FlowRL replaces standard reward maximization with reward distribution matching using a flow-balanced objective, enabling LLMs to explore diverse reasoning paths without collapsing to a single dominant solution.
Core Problem
Standard RL methods like PPO and GRPO maximize expected reward, causing the model to collapse to a single dominant reasoning pattern (mode collapse) and neglect other valid, less frequent solutions.
Why it matters:
- Mode collapse limits the diversity of generated reasoning paths, which reduces the model's ability to generalize to new, complex problems
- Effective Chain-of-Thought (CoT) reasoning requires exploring a diverse distribution of plausible solutions, not just memorizing the most common path
- Current methods struggle to balance exploration and exploitation in long-horizon reasoning tasks, leading to local optima
Concrete Example:
In math reasoning (e.g., GSM8K), GRPO might converge to a single template for solving a problem type. If that template fails on a variation, the model fails. FlowRL maintains multiple distinct solution paths, increasing the likelihood that at least one path succeeds.
Key Novelty
Flow-Balanced Policy Optimization (FlowRL)
- Treats RL as matching a target reward distribution rather than maximizing a scalar value, using a learnable partition function to normalize rewards into probabilities
- Adapts the trajectory balance objective from GFlowNets for large-scale LLM training, proving it approximates minimizing the reverse KL divergence to the target distribution
- Introduces length normalization to handle gradient instability in long CoT sequences and importance sampling to allow data reuse from old policies
Architecture
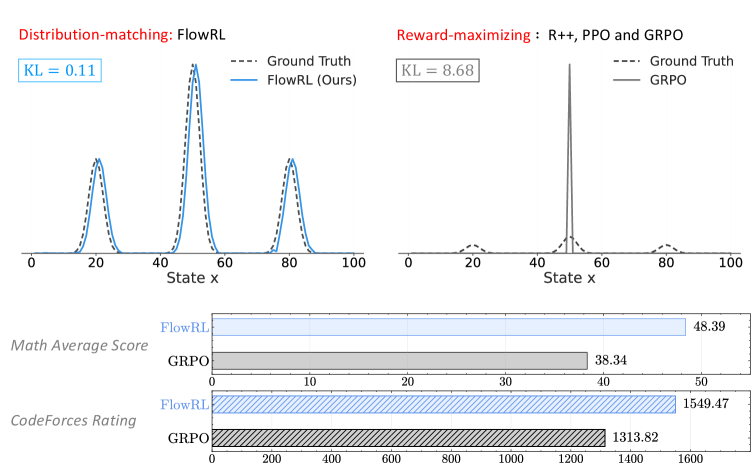
Comparison of GRPO (Reward Maximization) vs. FlowRL (Reward Distribution Matching). Left: GRPO pushes probability mass to a single dominant mode. Right: FlowRL aligns the policy distribution with the multi-modal reward distribution.
Evaluation Highlights
- +10.0% average improvement over GRPO on math benchmarks using Llama-3-8B-Instruct
- +5.1% average improvement over PPO on math benchmarks using Llama-3-8B-Instruct
- Consistently outperforms baselines on code reasoning tasks (LeetCode, LiveCodeBench, HumanEval) with both 7B and 32B models
Breakthrough Assessment
8/10
Offers a theoretically grounded alternative to standard PPO/GRPO that directly addresses the diversity/mode-collapse problem. Significant empirical gains on hard reasoning tasks suggest this is a strong direction for post-training reasoning models.