📝 Paper Summary
Critic-free Reinforcement Learning
RLHF (Reinforcement Learning from Human Feedback)
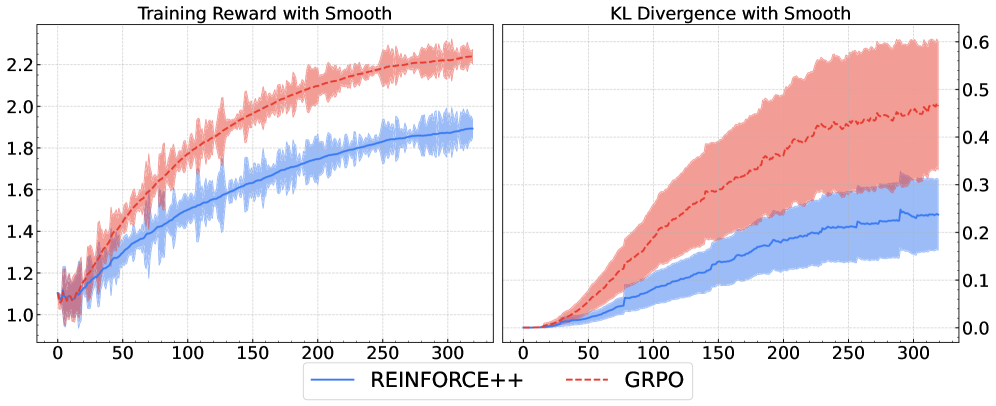
REINFORCE++ stabilizes critic-free RLHF by replacing biased prompt-level normalization with global advantage normalization, effectively preventing overfitting and reward hacking without a value network.
Core Problem
Critic-free algorithms like GRPO rely on prompt-level (local) normalization, which produces theoretically biased advantage estimates and unstable gradients when local variance is low.
Why it matters:
- Standard PPO requires a memory-intensive critic network, limiting the size of models that can be aligned on available hardware
- Local normalization in methods like GRPO encourages 'reward hacking' within a prompt group rather than learning globally good policies
- When sampled responses for a prompt have similar rewards, local standard deviation approaches zero, causing exploding gradients and training instability
Concrete Example:
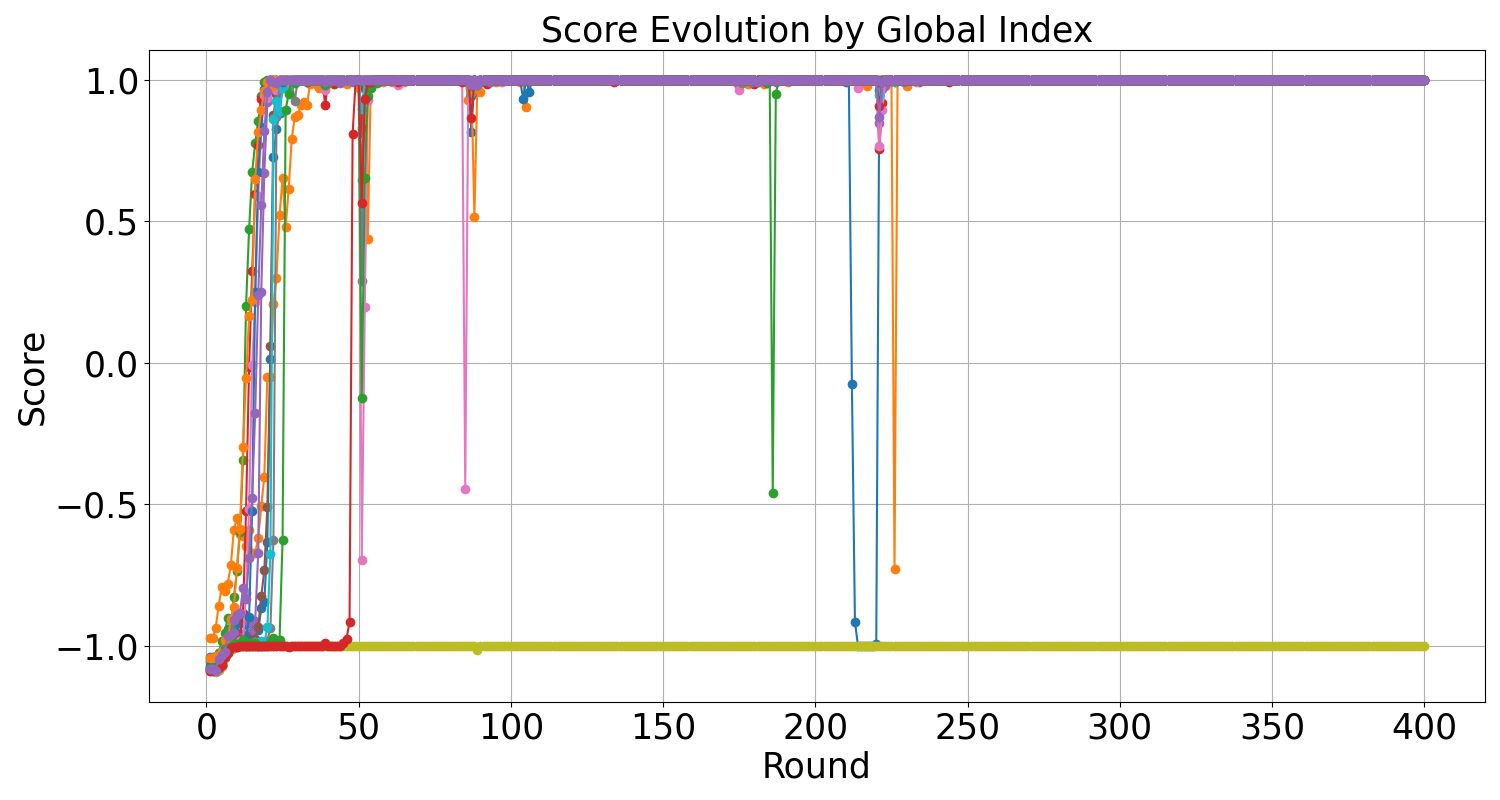
In a math reasoning task, GRPO achieves 95.0% accuracy on the training set (AIME-24) but 0.0% on the test set (AIME-25), demonstrating catastrophic overfitting because the model learns to 'win' the local group rather than solve the problem. REINFORCE++ achieves 40.0% Pass@16 on the test set.
Key Novelty
Global Advantage Normalization for Critic-Free RL
- Normalizes advantages using statistics (mean and standard deviation) calculated across the entire global training batch rather than small prompt-specific groups
- Uses a two-step estimation for complex tasks (k>1): first subtracts the group mean to reshape rewards (reduce variance), then applies global normalization for stability
- Adopts the k2 KL-divergence estimator which provides unbiased gradients for the reverse KL, unlike the unstable k3 estimator used in GRPO
Architecture
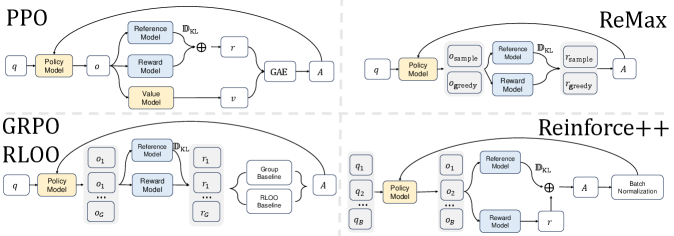
Comparison of PPO, ReMax, RLOO, GRPO, and REINFORCE++ architectures and advantage formulations.
Evaluation Highlights
- Outperforms GRPO on out-of-distribution math reasoning (AIME-25), achieving 40.0 Pass@16 compared to GRPO's 0.0, despite GRPO's near-perfect training score.
- Surpasses PPO (Proximal Policy Optimization) on complex agentic tasks (Average@32 across 4 benchmarks) with a score of 24.10 vs PPO's 21.85, without needing a critic network.
- Achieves higher token efficiency in general RLHF: 0.0561 score/token vs GRPO's 0.0544, by generating more concise responses while matching total reward.
Breakthrough Assessment
8/10
Addresses a fundamental theoretical flaw (bias) in widely used critic-free methods like GRPO. The empirical demonstration of preventing catastrophic overfitting in reasoning tasks is highly significant.