📝 Paper Summary
Off-policy Reinforcement Learning
LLM Alignment
Mathematical Reasoning
BAPO stabilizes off-policy LLM training by dynamically adjusting clipping bounds to balance positive and negative sample contributions, preventing gradient domination by negative samples and preserving exploration entropy.
Core Problem
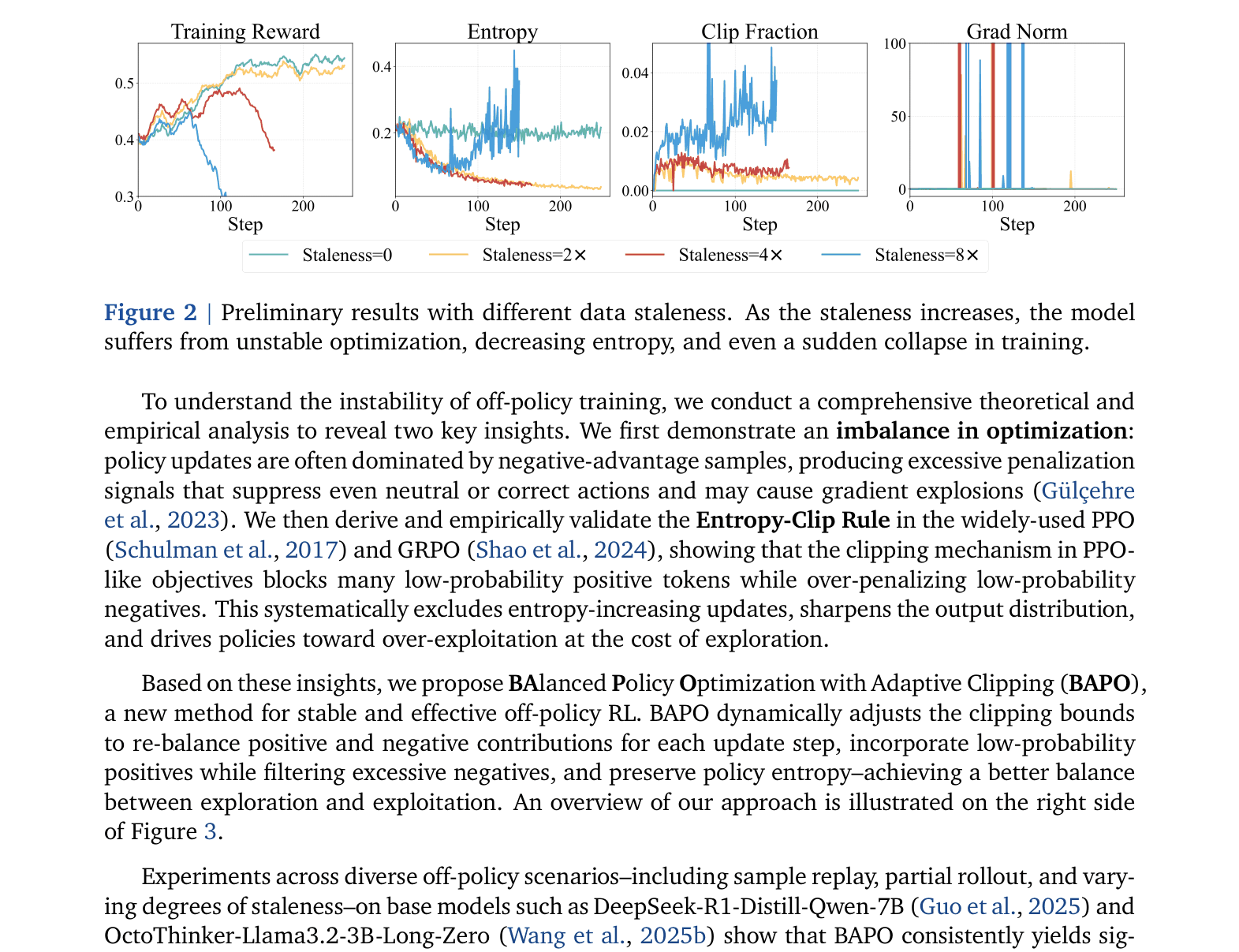
Off-policy RL (using stale data) for LLMs suffers from sharp entropy decline and unstable optimization because standard clipping mechanisms block entropy-increasing updates while allowing negative samples to dominate gradients.
Why it matters:
- Off-policy training improves sample efficiency and enables advanced infrastructure like partial rollouts, but current instability (gradient explosions, collapse) prevents its widespread use.
- Standard PPO/GRPO clipping unintentionally suppresses exploration by filtering out low-probability positive tokens, driving the policy toward premature over-exploitation.
- As data staleness increases in large-scale training (e.g., experience replay), performance degrades rapidly with existing methods.
Concrete Example:
In a reasoning task, a model might generate a correct but low-probability intermediate step. Standard PPO clips this positive update because the probability ratio is outside [0.8, 1.2], blocking the 'surprise' signal needed to increase entropy. Meanwhile, incorrect long chain-of-thought traces generate massive negative gradients that aren't effectively clipped, overwhelming the optimizer.
Key Novelty
Balanced Policy Optimization with Adaptive Clipping (BAPO)
- Dynamically adjusts the upper and lower clipping bounds ($c_{high}$, $c_{low}$) per batch to ensure positive samples contribute a target proportion ($ ho_0$) to the total loss.
- Asymmetrically expands the clipping range for positive tokens to include valid but low-probability actions (increasing entropy) while strictly filtering excessive negative tokens to prevent gradient explosion.
Architecture
Conceptual comparison between GRPO's symmetric clipping and BAPO's adaptive asymmetric clipping.
Evaluation Highlights
- BP-Math-32B BAPO achieves 87.1% on AIME 2024, outperforming proprietary o3-mini-medium (79.6%) and open-source SkyWork-OR1-32B (82.2%).
- BP-Math-7B BAPO reaches 70.8% on AIME 2024, surpassing SkyWork-OR1-7B (70.2%) and achieving results comparable to Gemini-2.0 Flash-Thinking.
- Maintains training stability even with 8x data staleness, whereas baseline GRPO suffers performance collapse under the same conditions.
Breakthrough Assessment
8/10
BAPO effectively solves the notorious instability of off-policy RL for LLMs, enabling highly efficient training pipelines (like partial rollouts) while achieving SOTA results against proprietary models.