📊 Experiments & Results
Evaluation Setup
Multilingual mathematical reasoning across 10 languages (English + 9 others)
Benchmarks:
- MGSM (Grade school math reasoning)
- MSVAMP (Math word problems (Out-of-domain test set))
- MNumGLUESub (Arithmetic reasoning (In-domain preference source)) [New]
Metrics:
- Accuracy
- Answer Consistency Ratio (ACR)
- PPL-based Alignment Score
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| MAPO consistently outperforms baselines across diverse benchmarks, with particularly large gains on the out-of-domain MSVAMP dataset. | ||||
| MSVAMP | Accuracy | 43.3 | 59.5 | +16.2 |
| MNumGLUESub | Accuracy | 46.2 | 59.5 | +13.3 |
| MGSM | Accuracy | 45.7 | 51.8 | +6.1 |
| MSVAMP | Accuracy | 50.9 | 65.6 | +14.7 |
| MSVAMP | Accuracy | 67.8 | 74.6 | +6.8 |
| Low-resource languages see the most significant benefits from alignment. | ||||
| MSVAMP | Accuracy (Bengali) | Not reported in the paper | Not reported in the paper | +21.1 |
| MSVAMP | Accuracy (Thai) | Not reported in the paper | Not reported in the paper | +19.3 |
Experiment Figures
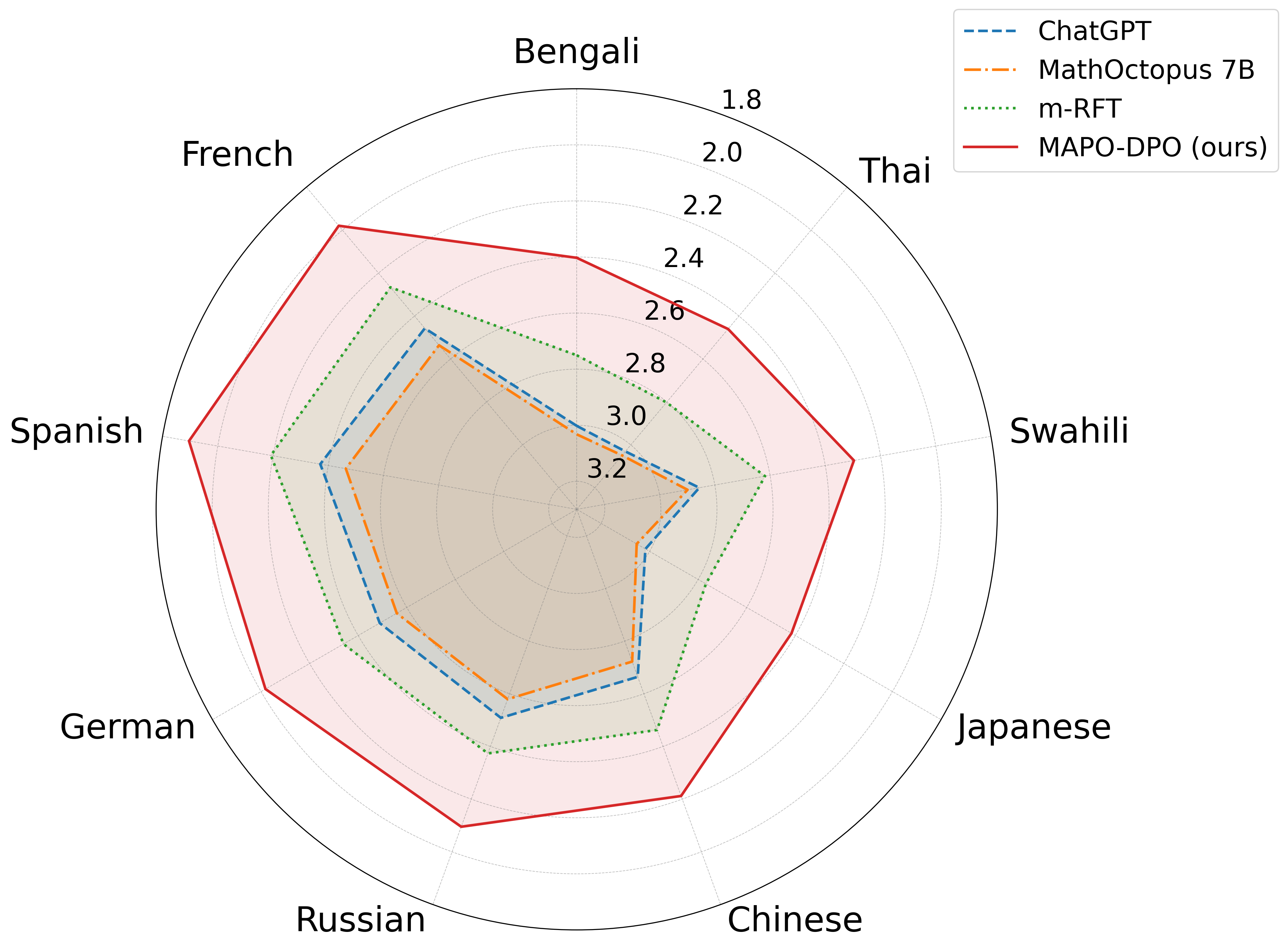
Visualization of reasoning process alignment consistency
Main Takeaways
- MAPO significantly improves reasoning generalization, evidenced by the massive +16.2% gain on the out-of-domain MSVAMP dataset
- Low-resource languages (Bengali, Thai, Swahili) benefit most from alignment, with gains around +20%
- Even English performance improves slightly (despite being the reference), suggesting that enforcing cross-lingual consistency refines general reasoning capabilities
- Reasoning consistency (measured by ACR) improves, indicating the model is not just guessing correctly but reasoning similarly across languages