📝 Paper Summary
Language Model Alignment
Multi-Objective Optimization
MOD combines output distributions from multiple single-objective aligned models at decoding time to optimally satisfy arbitrary preference weightings without retraining.
Core Problem
Existing alignment methods (like PPO/DPO) optimize for a single reward function, but real-world applications require trading off multiple conflicting objectives (e.g., helpfulness vs. safety) based on varying user preferences.
Why it matters:
- Retraining models for every possible combination of user preferences is computationally prohibitive
- Prompt engineering fails to provide precise, granular control over the weighting of output characteristics
- Parameter merging (weight interpolation) is theoretically sub-optimal for non-linear objectives like KL-divergence regularization
Concrete Example:
A dialogue agent needs to balance 'helpfulness' and 'harmlessness'. A user might want 70% helpfulness and 30% safety, while another wants 50/50. Current methods require either retraining a new model for each ratio or hoping a single model can generalize, often failing to hit the specific desired trade-off.
Key Novelty
Multi-Objective Decoding (MOD) via Legendre Transform
- Uses the mathematical property (Legendre transform) of f-divergence regularized objectives (like PPO/DPO) to derive a closed-form solution for optimal multi-objective policies
- Show that the optimal policy for a weighted sum of rewards is a weighted geometric mean of the base policies (for KL-divergence), not a linear interpolation of weights
- Implements this solution as a simple token-level decoding strategy that linearly combines the logits of base models according to preference weights
Architecture

Illustration of the MOD pipeline compared to training-based methods. It shows multiple base models processing the same input, their output distributions being aggregated via a weighted geometric mean (linear in log-space), resulting in a final token distribution.
Evaluation Highlights
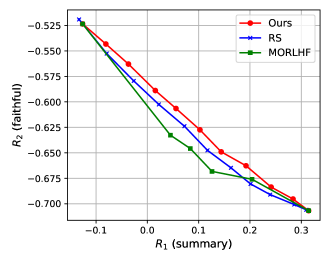
- +12.8% overall reward improvement compared to parameter merging (Rewarded Soups) when equally optimizing three objectives on the Helpful Assistant task
- Reduces toxicity to nearly 0% while achieving 7.9% to 33.3% improvement across three other metrics (Codex@1, GSM-COT, BBH-COT) when combining three Tülu models
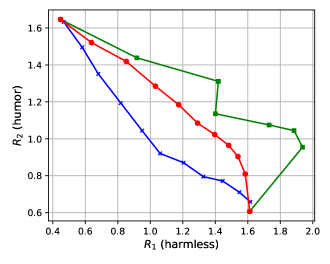
- Successfully combines heterogeneous models (two 13B DPO models and one 7B SFT model) for open instruction following, demonstrating flexibility across scales and training methods
Breakthrough Assessment
8/10
Provides a strong theoretical foundation (convex optimization) for a simple, effective practical method (logit mixing). Solves the multi-objective problem without retraining, a significant efficiency gain.