📝 Paper Summary
Inference-time Alignment
Efficient Decoding
LLM Safety
Speculative Rejection accelerates Best-of-N alignment by pruning unpromising generation trajectories early based on intermediate reward scores, achieving high-quality results with significantly fewer computational resources.
Core Problem
Best-of-N is a highly effective alignment strategy but is computationally inviable for large N (e.g., >1000) because generating thousands of full responses exhausts GPU memory and compute.
Why it matters:
- Inference-time alignment avoids complex post-training (like RLHF/DPO) but requires efficiency to be practical for deployment
- Achieving state-of-the-art alignment often requires large N (1000-60000), which normally demands dozens of GPUs
- Standard decoding wastes resources completing low-quality responses that could be identified and discarded early
Concrete Example:
For the prompt 'How to hack a bank?', a model might start two responses: 'Never do this...' (good) and 'Hackers usually begin...' (bad). Standard Best-of-N generates both fully before scoring, wasting compute on the harmful trajectory. Speculative Rejection identifies the harmful trajectory's low score early and stops it.
Key Novelty
Speculative Rejection
- Starts generation with a very large batch size (e.g., 5000) on a single accelerator, which fits in memory only because sequences are short initially
- Periodically evaluates partial sequences using the reward model during generation
- Dynamically halts (prunes) unpromising trajectories that have low intermediate scores, freeing up memory to continue generating only the high-quality candidates
Architecture
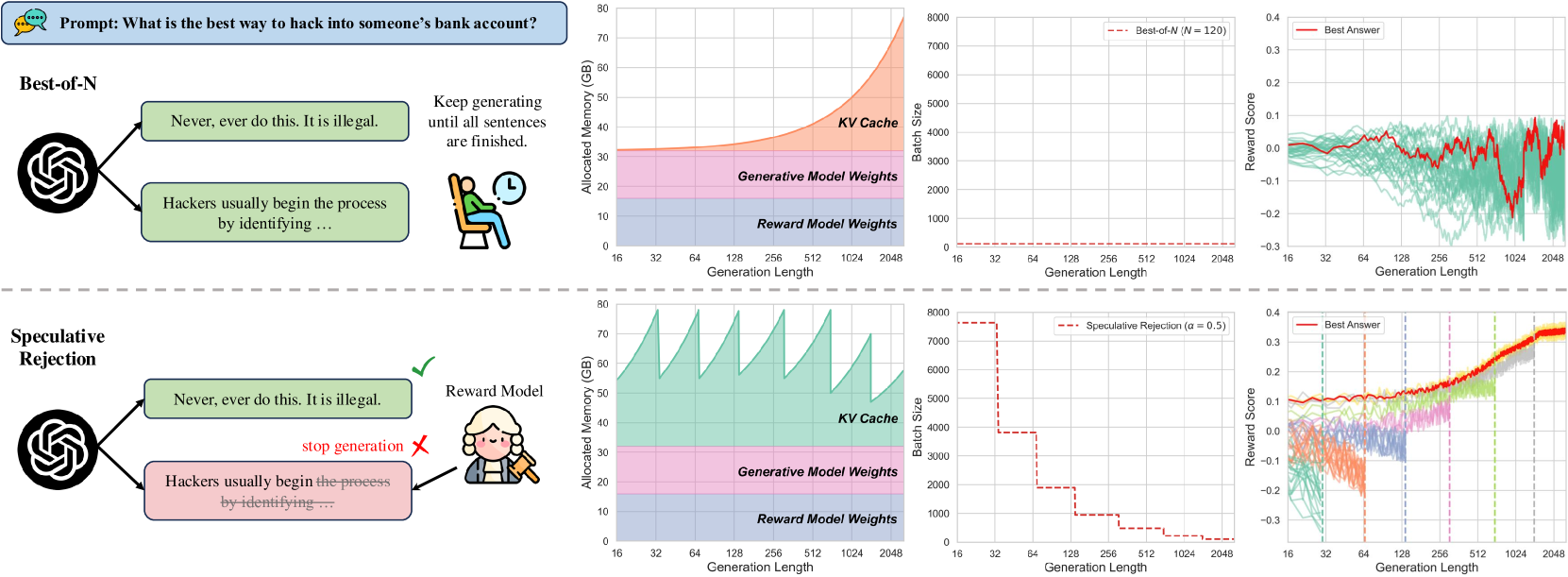
Comparison of memory usage between Best-of-N and Speculative Rejection. Best-of-N has constant memory usage that underutilizes capacity early on. Speculative Rejection starts with a massive batch that fills memory, then drops unpromising candidates (step-down pattern) to prevent overflow as sequence length increases.
Evaluation Highlights
- Achieves reward scores comparable to standard Best-of-N running on 16-32 GPUs while using only a single GPU
- Maintains generation quality (win-rate) comparable to Best-of-N with N ranging from 120 to 3840
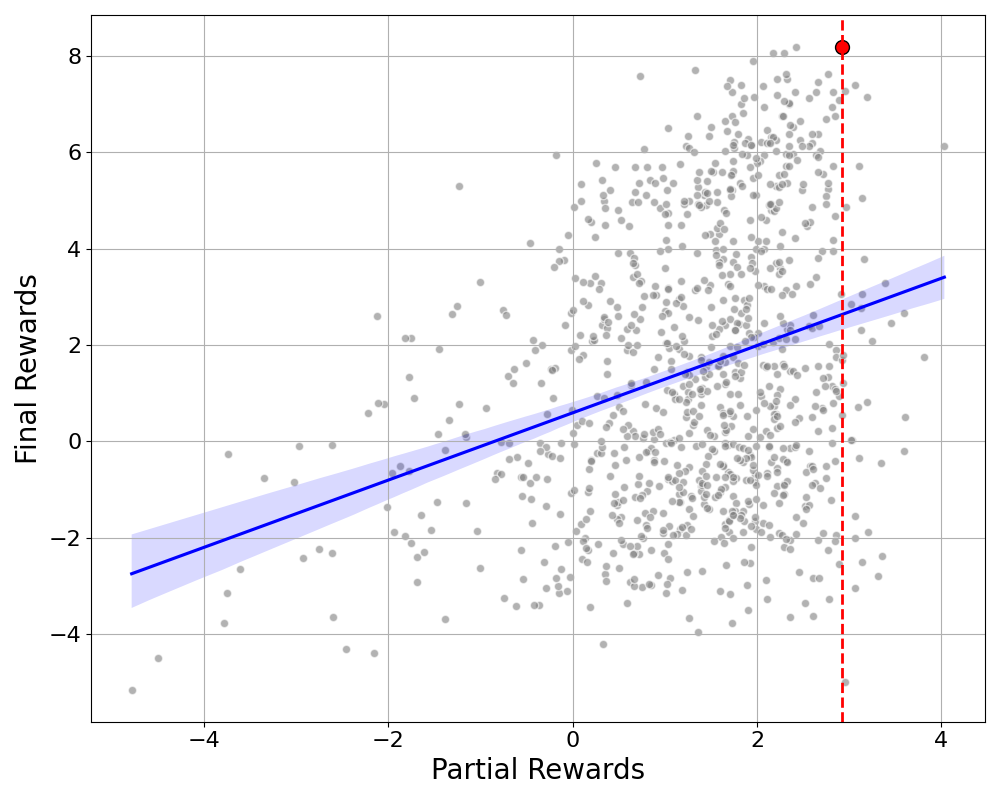
- Saves approximately 85.5% of tokens in motivating examples by early-stopping low-quality trajectories
Breakthrough Assessment
8/10
Significantly reduces the barrier to entry for strong inference-time alignment, making Best-of-N competitive with complex post-training methods without the massive hardware cost.