📝 Paper Summary
Reinforcement Learning with Generative Models
Continuous Control
FPO adapts the PPO algorithm to flow-based models by replacing exact likelihood ratios with a tractable ratio of flow matching losses, enabling stable training of expressive continuous control policies.
Core Problem
Standard policy gradient methods like PPO require exact log-likelihoods, which are computationally prohibitive for flow-based models, while existing diffusion RL methods restrict training to specific sampling chains and increase credit assignment difficulty.
Why it matters:
- Gaussian policies commonly used in RL cannot model multimodal distributions, limiting performance in complex or under-conditioned tasks.
- Prior diffusion RL methods (like DDPO) frame denoising as an MDP, which explodes the horizon length and binds the learned policy to a specific sampler configuration.
Concrete Example:
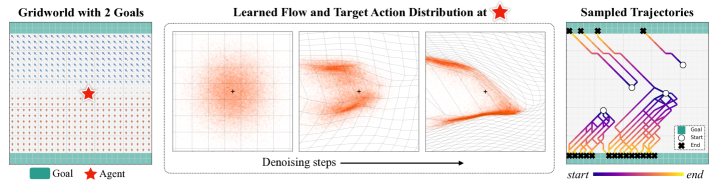
In a GridWorld state with multiple optimal paths, a Gaussian policy averages conflicting actions (choosing the middle), whereas a flow policy can represent the multimodal distribution of distinct valid actions.
Key Novelty
Flow Policy Optimization (FPO)
- Replaces the intractable likelihood ratio in PPO with a proxy ratio derived from the difference in conditional flow matching losses (ELBOs) between the new and old policies.
- Treats the flow generation process as a black box during rollouts, making the training algorithm agnostic to the choice of ODE solver, step count, or stochasticity used for sampling.
Architecture
The pseudocode for Flow Policy Optimization (FPO) integrated with PPO
Evaluation Highlights
- Demonstrates capability to learn multimodal action distributions in GridWorld environments where Gaussian policies fail.
- Achieves higher performance than Gaussian policies in under-conditioned humanoid control tasks by effectively modeling complex action distributions.
- Successfully trains diffusion-style policies from scratch on 10 continuous control tasks from MuJoCo Playground.
Breakthrough Assessment
8/10
FPO provides a theoretically grounded and practically simple way to apply PPO to flow matching models without the complexity of prior MDP-based diffusion RL approaches.