📝 Paper Summary
Reinforcement Learning for LLMs
Efficient Training Methods
Mathematical Reasoning
GRESO improves RL training efficiency by predicting and skipping uninformative prompts (those yielding zero reward variance) before the expensive rollout stage, leveraging the temporal consistency of prompt difficulty.
Core Problem
Scaling up rollouts in RL improves model performance but introduces massive computational overhead, as many prompts yield 'zero variance' (identical rewards across all responses) and provide no learning signal.
Why it matters:
- Rollout is a major bottleneck in RL training (e.g., PPO, GRPO), consuming significant GPU hours
- Existing methods like Dynamic Sampling filter uninformative data only *after* generating it, wasting computation on useless samples
- Static dataset pruning fails to adapt to the model's evolving capabilities during training
Concrete Example:
In GRPO, if a prompt like '2+2' always yields the same reward (whether correct or incorrect) across 16 samples, the advantage is zero and no learning occurs. Standard methods generate all 16 samples before realizing this; GRESO predicts this outcome beforehand and skips generation entirely.
Key Novelty
GRPO with Efficient Selective Rollout (GRESO)
- Identify 'zero-variance' prompts (prompts where all responses get identical rewards) as uninformative because they produce zero advantage signal
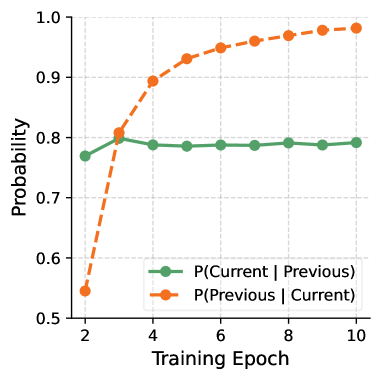
- Leverage 'temporal consistency': prompts that were zero-variance in previous epochs are highly likely to remain so in the current epoch
- Implement an online probabilistic filter that skips these prompts before rollout, using an adaptive exploration rate to occasionally re-check them
Architecture
The GRESO workflow comparing standard rollout vs. selective rollout.
Evaluation Highlights
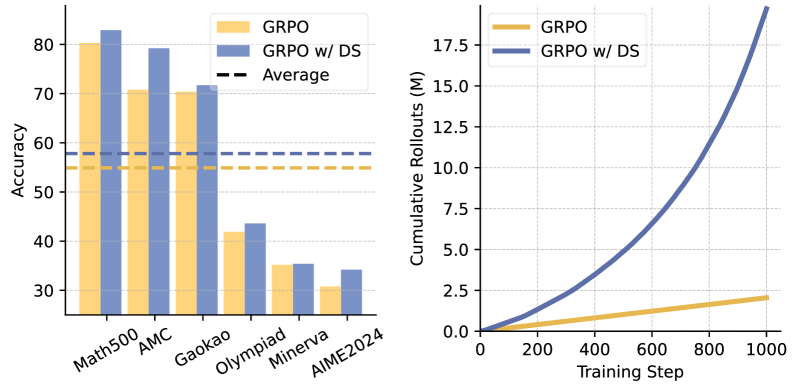
- Achieves up to 2.4x speedup in rollout time and 2.0x speedup in total training time compared to standard GRPO with Dynamic Sampling
- Maintains comparable accuracy on math reasoning benchmarks (e.g., GSM8K, MATH) while processing significantly fewer uninformative prompts
- Demonstrated effectiveness across multiple models, including Qwen2.5-Math-1.5B, DeepSeek-R1-Distill-Qwen-1.5B, and Qwen2.5-Math-7B
Breakthrough Assessment
7/10
Simple yet highly effective efficiency improvement for RLVR. While primarily an engineering optimization rather than a fundamental algorithmic shift, the speedups (2x) are practically significant for scaling LLM reasoning.