📝 Paper Summary
Mathematical Reasoning
Process Reward Models (PRM)
Reinforcement Learning from Feedback
MATH-SHEPHERD automates the training of process reward models by verifying intermediate reasoning steps through Monte Carlo-style rollouts, eliminating the need for expensive human annotations.
Core Problem
Process Reward Models (PRMs) improve reasoning reliability but traditionally require costly and hard-to-scale human annotations to label individual steps as correct or incorrect.
Why it matters:
- Human annotation for complex multi-step math problems requires high skill levels and is prohibitively expensive to scale
- Outcome Reward Models (ORMs) only grade the final answer, failing to identify specific errors in the reasoning chain, which limits feedback quality for reinforcement learning
- Relying solely on top-1 generation from LLMs is unreliable; effective verification is needed to select correct solutions from candidates
Concrete Example:
In a polynomial problem requiring $p(0) + p(4)$, an ORM might mark a solution with the wrong answer '20' as incorrect (0 score). However, the solution might have a correct first step (factoring the polynomial correctly) followed by a calculation error. An ORM misses this nuance, whereas a PRM can reward the correct first step while penalizing the subsequent error.
Key Novelty
Automatic Process Annotation via Reasoning Rollouts
- Defines the quality of an intermediate step by its potential to reach the correct final answer, inspired by Monte Carlo Tree Search
- Uses a 'completer' model to generate multiple future paths from a specific step; if these paths lead to the ground truth answer, the step is automatically labeled as valid
- Constructs a massive supervised dataset of step-wise labels without human intervention to train a Process Reward Model
Architecture

Comparison between automatic Outcome Annotation and the proposed Automatic Process Annotation pipeline
Evaluation Highlights
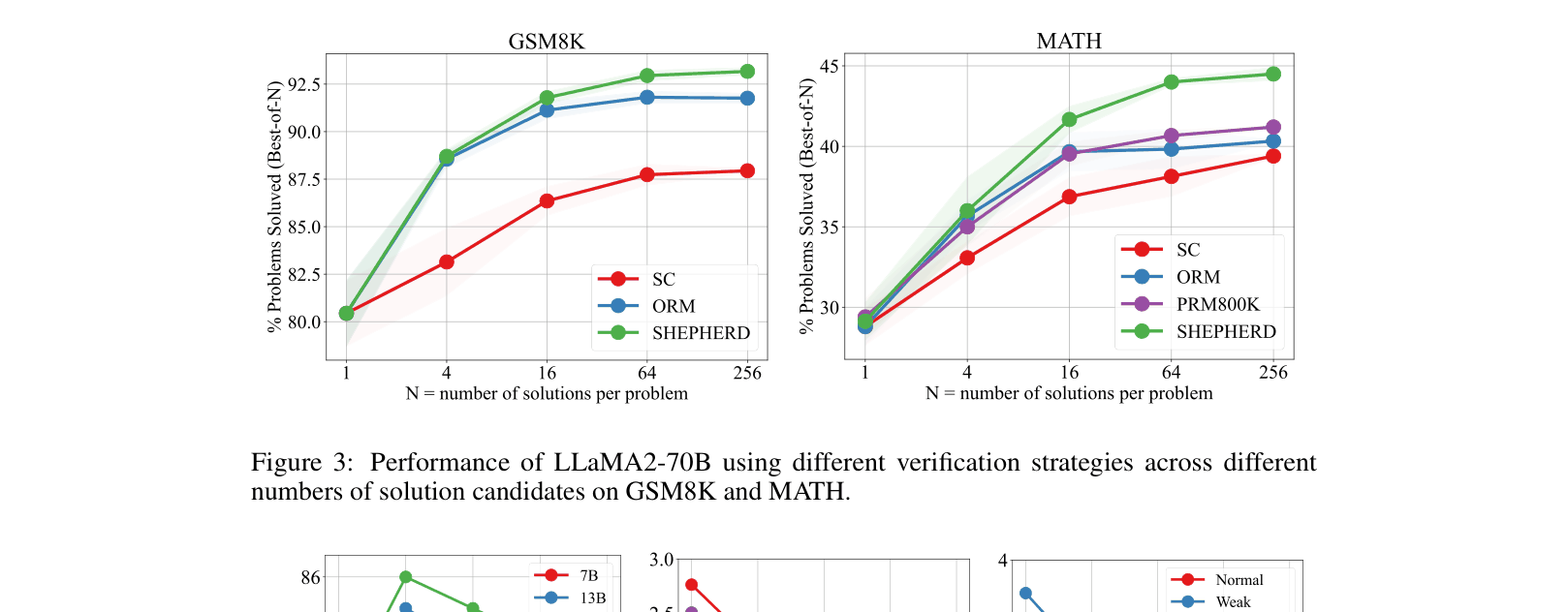
- DeepSeek-67B with MATH-SHEPHERD verification achieves 93.3% accuracy on GSM8K (+5.1% over Self-Consistency)
- Mistral-7B trained with step-by-step PPO using MATH-SHEPHERD improves from 28.6% to 33.0% on the MATH dataset
- LLaMA2-70B with MATH-SHEPHERD verification achieves 44.5% on MATH500, outperforming Outcome Reward Models (40.4%) and Self-Consistency (39.4%)
Breakthrough Assessment
8/10
Significantly lowers the barrier for training Process Reward Models by removing the human annotation bottleneck. Achieves state-of-the-art results on open-source models without external tools.